 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance formulas capable of unifying Euclidian space and probability space
Paper and Code
Jan 06, 2018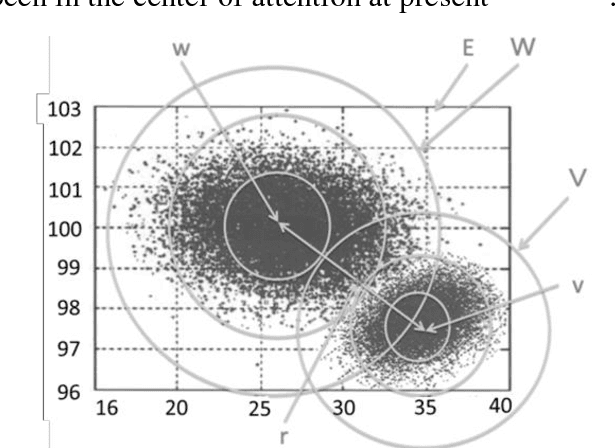
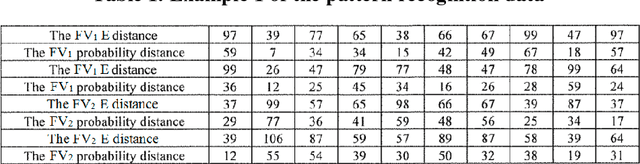
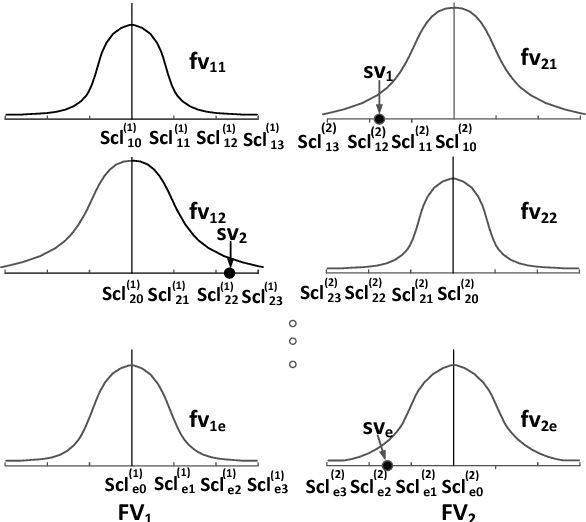
For pattern recognition like image recognition, it has become clear that each machine-learning dictionary data actually became data in probability space belonging to Euclidean space. However, the distances in the Euclidean space and the distances in the probability space are separated and ununified when machine learning is introduced in the pattern recognition. There is still a problem that it is impossible to directly calculate an accurate matching relation between the sampling data of the read image and the learned dictionary data. In this research, we focused on the reason why the distance is changed and the extent of change when passing through the probability space from the original Euclidean distance among data belonging to multiple probability spaces containing Euclidean space. By finding the reason of the cause of the distance error and finding the formula expressing the error quantitatively, a possible distance formula to unify Euclidean space and probability space is found. Based on the results of this research, the relationship between machine-learning dictionary data and sampling data was clearly understood for pattern recognition. As a result, the calculation of collation among data and machine-learning to compete mutually between data are cleared, and complicated calculations became unnecessary. Finally, using actual pattern recognition data, experimental demonstration of a possible distance formula to unify Euclidean space and probability space discovered by this research was carried out, and the effectiveness of the result was confirmed.