 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisrupting Diffusion: Token-Level Attention Erasure Attack against Diffusion-based Customization
Paper and Code
May 31, 2024
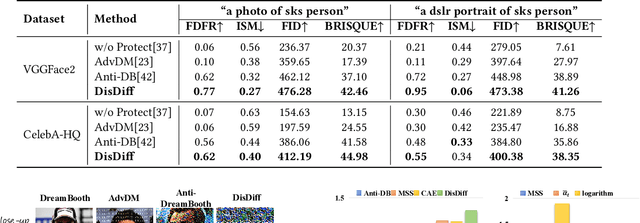
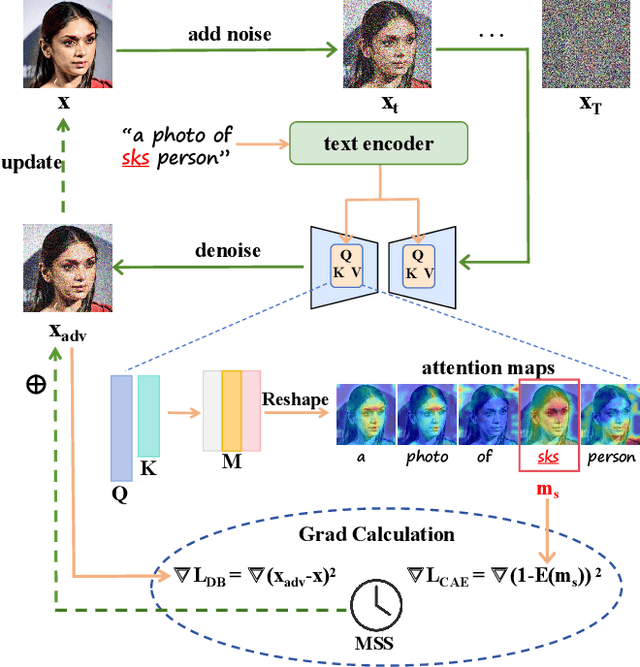
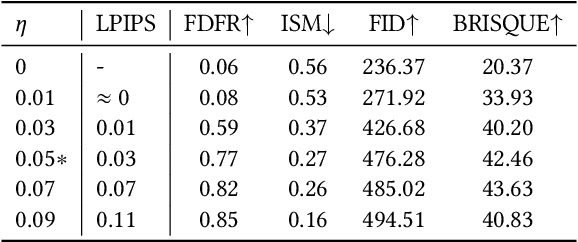
With the development of diffusion-based customization methods like DreamBooth, individuals now have access to train the models that can generate their personalized images. Despite the convenience, malicious users have misused these techniques to create fake images, thereby triggering a privacy security crisis. In light of this, proactive adversarial attacks are proposed to protect users against customization. The adversarial examples are trained to distort the customization model's outputs and thus block the misuse. In this paper, we propose DisDiff (Disrupting Diffusion), a novel adversarial attack method to disrupt the diffusion model outputs. We first delve into the intrinsic image-text relationships, well-known as cross-attention, and empirically find that the subject-identifier token plays an important role in guiding image generation. Thus, we propose the Cross-Attention Erasure module to explicitly "erase" the indicated attention maps and disrupt the text guidance. Besides,we analyze the influence of the sampling process of the diffusion model on Projected Gradient Descent (PGD) attack and introduce a novel Merit Sampling Scheduler to adaptively modulate the perturbation updating amplitude in a step-aware manner. Our DisDiff outperforms the state-of-the-art methods by 12.75% of FDFR scores and 7.25% of ISM scores across two facial benchmarks and two commonly used prompts on average.