Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisambiguation-BERT for N-best Rescoring in Low-Resource Conversational ASR
Paper and Code
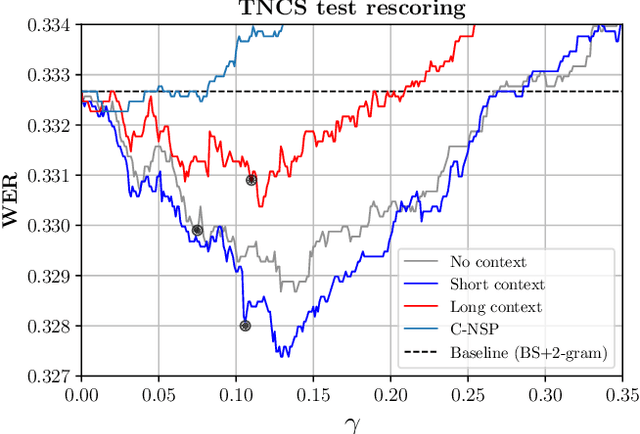
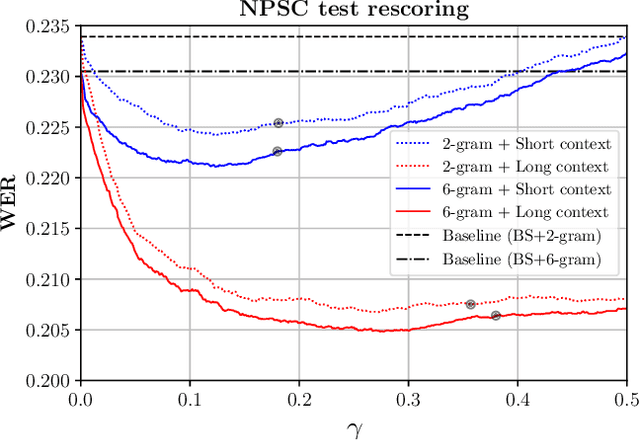
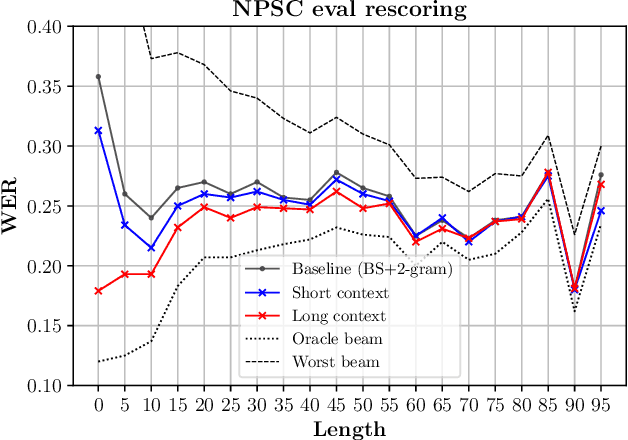
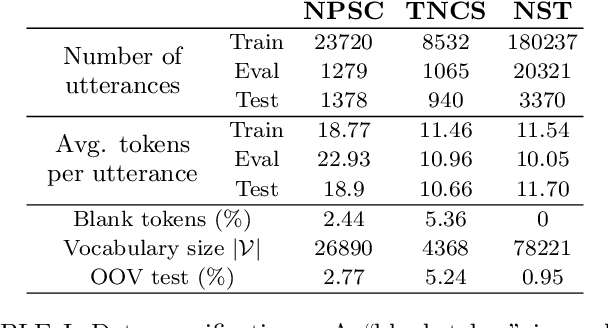
We study the inclusion of past conversational context through BERT language models into a CTC-based Automatic Speech Recognition (ASR) system via N-best rescoring. We introduce a data-efficient strategy to fine-tune BERT on transcript disambiguation without external data. Our results show word error rate recoveries up to 37.2% with context-augmented BERT rescoring. We do this in low-resource data domains, both in language (Norwegian), tone (spontaneous, conversational), and topics (parliament proceedings and customer service phone calls). We show how the nature of the data greatly affects the performance of context-augmented N-best rescoring.
* 9 pages, 3 figures
View paper on