 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisambiguating Symbolic Expressions in Informal Documents
Paper and Code


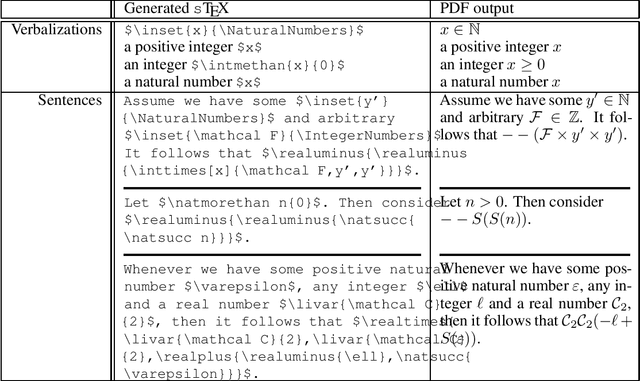
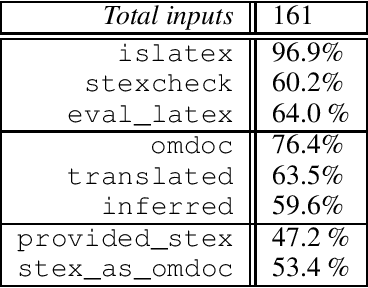
We propose the task of disambiguating symbolic expressions in informal STEM documents in the form of LaTeX files - that is, determining their precise semantics and abstract syntax tree - as a neural machine translation task. We discuss the distinct challenges involved and present a dataset with roughly 33,000 entries. We evaluated several baseline models on this dataset, which failed to yield even syntactically valid LaTeX before overfitting. Consequently, we describe a methodology using a transformer language model pre-trained on sources obtained from arxiv.org, which yields promising results despite the small size of the dataset. We evaluate our model using a plurality of dedicated techniques, taking the syntax and semantics of symbolic expressions into account.