Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Uncertainty Estimation in Reinforcement Learning
Paper and Code
Jun 25, 2013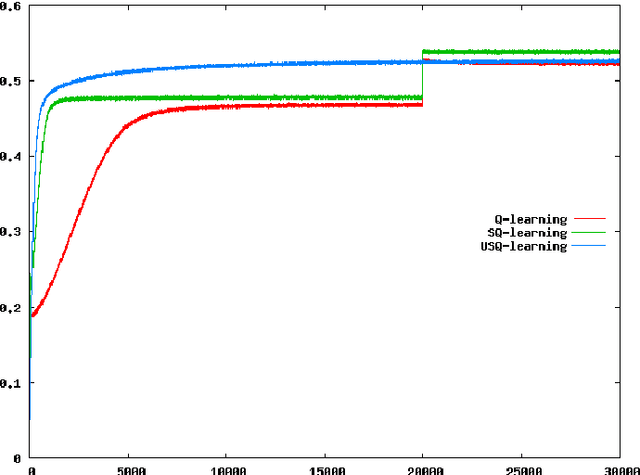
Optimal probabilistic approach in reinforcement learning is computationally infeasible. Its simplification consisting in neglecting difference between true environment and its model estimated using limited number of observations causes exploration vs exploitation problem. Uncertainty can be expressed in terms of a probability distribution over the space of environment models, and this uncertainty can be propagated to the action-value function via Bellman iterations, which are computationally insufficiently efficient though. We consider possibility of directly measuring uncertainty of the action-value function, and analyze sufficiency of this facilitated approach.
* AGI-13 Workshop paper
View paper on