 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionCLIP: Text-guided Image Manipulation Using Diffusion Models
Paper and Code

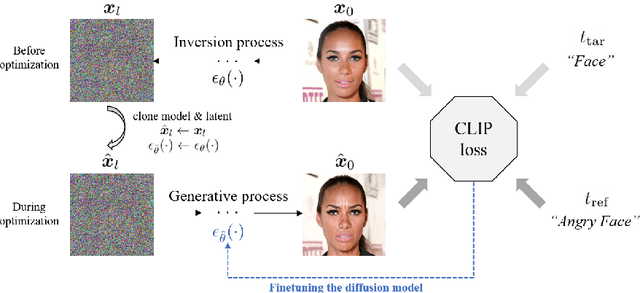


Diffusion models are recent generative models that have shown great success in image generation with the state-of-the-art performance. However, only a few researches have been conducted for image manipulation with diffusion models. Here, we present a novel DiffusionCLIP which performs text-driven image manipulation with diffusion models using Contrastive Language-Image Pre-training (CLIP) loss. Our method has a performance comparable to that of the modern GAN-based image processing methods for in and out-of-domain image processing tasks, with the advantage of almost perfect inversion even without additional encoders or optimization. Furthermore, our method can be easily used for various novel applications, enabling image translation from an unseen domain to another unseen domain or stroke-conditioned image generation in an unseen domain, etc. Finally, we present a novel multiple attribute control with DiffusionCLIPby combining multiple fine-tuned diffusion models.