 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models for Zero-Shot Open-Vocabulary Segmentation
Paper and Code

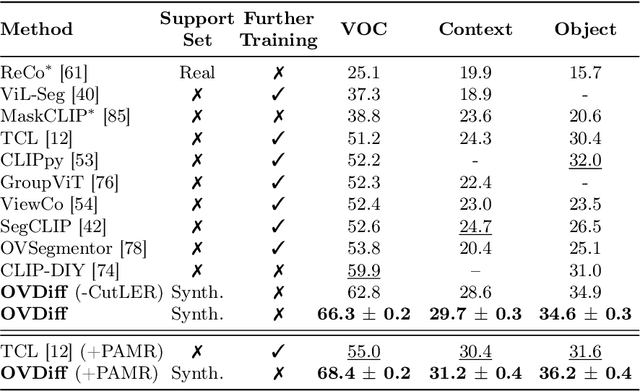
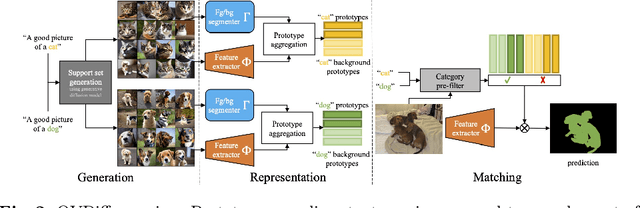

The variety of objects in the real world is nearly unlimited and is thus impossible to capture using models trained on a fixed set of categories. As a result, in recent years, open-vocabulary methods have attracted the interest of the community. This paper proposes a new method for zero-shot open-vocabulary segmentation. Prior work largely relies on contrastive training using image-text pairs, leveraging grouping mechanisms to learn image features that are both aligned with language and well-localised. This however can introduce ambiguity as the visual appearance of images with similar captions often varies. Instead, we leverage the generative properties of large-scale text-to-image diffusion models to sample a set of support images for a given textual category. This provides a distribution of appearances for a given text circumventing the ambiguity problem. We further propose a mechanism that considers the contextual background of the sampled images to better localise objects and segment the background directly. We show that our method can be used to ground several existing pre-trained self-supervised feature extractors in natural language and provide explainable predictions by mapping back to regions in the support set. Our proposal is training-free, relying on pre-trained components only, yet, shows strong performance on a range of open-vocabulary segmentation benchmarks, obtaining a lead of more than 10% on the Pascal VOC benchmark.