 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Weighted Sampling
Paper and Code
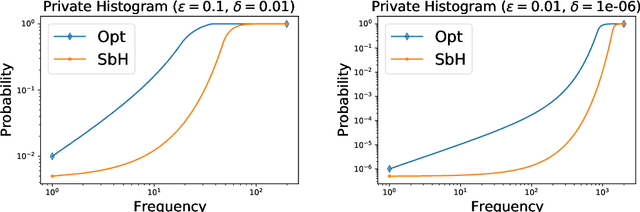
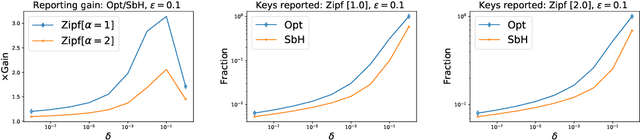
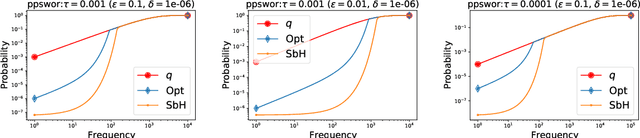
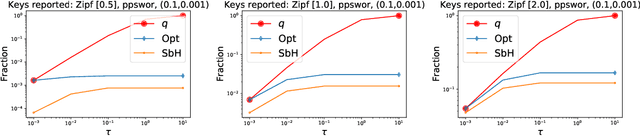
Common datasets have the form of {\em elements} with {\em keys} (e.g., transactions and products) and the goal is to perform analytics on the aggregated form of {\em key} and {\em frequency} pairs. A weighted sample of keys by (a function of) frequency is a highly versatile summary that provides a sparse set of representative keys and supports approximate evaluations of query statistics. We propose {\em private weighted sampling} (PWS): A method that ensures element-level differential privacy while retaining, to the extent possible, the utility of a respective non-private weighted sample. PWS maximizes the reporting probabilities of keys and improves over the state of the art also for the well-studied special case of {\em private histograms}, when no sampling is performed. We empirically demonstrate significant performance gains compared with prior baselines: 20\%-300\% increase in key reporting for common Zipfian frequency distributions and accuracy for $\times 2$-$ 8$ lower frequencies in estimation tasks. Moreover, PWS is applied as a simple post-processing of a non-private sample, without requiring the original data. This allows for seamless integration with existing implementations of non-private schemes and retaining the efficiency of schemes designed for resource-constrained settings such as massive distributed or streamed data. We believe that due to practicality and performance, PWS may become a method of choice in applications where privacy is desired.