 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Deep Learning with ModelMix
Paper and Code
Oct 07, 2022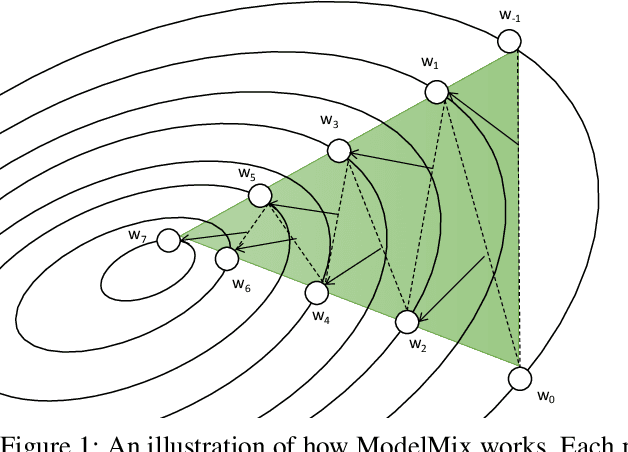

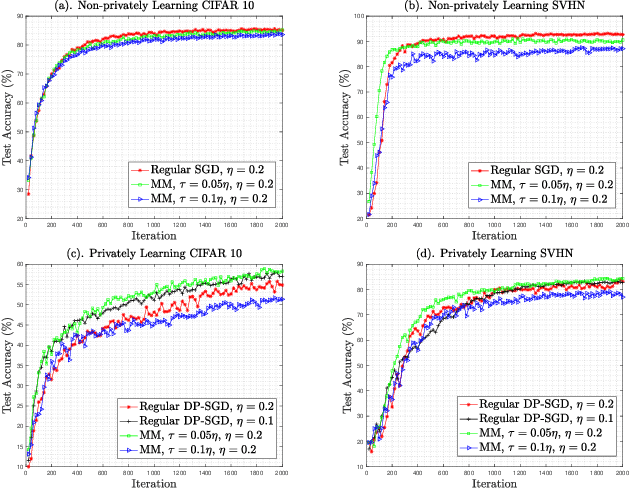

Training large neural networks with meaningful/usable differential privacy security guarantees is a demanding challenge. In this paper, we tackle this problem by revisiting the two key operations in Differentially Private Stochastic Gradient Descent (DP-SGD): 1) iterative perturbation and 2) gradient clipping. We propose a generic optimization framework, called {\em ModelMix}, which performs random aggregation of intermediate model states. It strengthens the composite privacy analysis utilizing the entropy of the training trajectory and improves the $(\epsilon, \delta)$ DP security parameters by an order of magnitude. We provide rigorous analyses for both the utility guarantees and privacy amplification of ModelMix. In particular, we present a formal study on the effect of gradient clipping in DP-SGD, which provides theoretical instruction on how hyper-parameters should be selected. We also introduce a refined gradient clipping method, which can further sharpen the privacy loss in private learning when combined with ModelMix. Thorough experiments with significant privacy/utility improvement are presented to support our theory. We train a Resnet-20 network on CIFAR10 with $70.4\%$ accuracy via ModelMix given $(\epsilon=8, \delta=10^{-5})$ DP-budget, compared to the same performance but with $(\epsilon=145.8,\delta=10^{-5})$ using regular DP-SGD; assisted with additional public low-dimensional gradient embedding, one can further improve the accuracy to $79.1\%$ with $(\epsilon=6.1, \delta=10^{-5})$ DP-budget, compared to the same performance but with $(\epsilon=111.2, \delta=10^{-5})$ without ModelMix.