Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Privacy for Multi-armed Bandits: What Is It and What Is Its Cost?
Paper and Code
May 29, 2019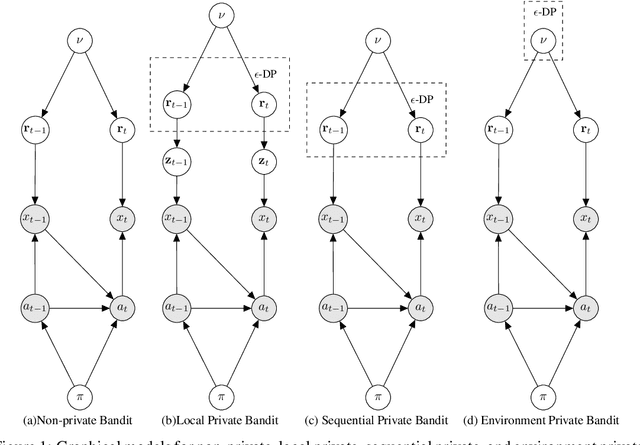
We introduce a number of privacy definitions for the multi-armed bandit problem, based on differential privacy. We relate them through a unifying graphical model representation and connect them to existing definitions. We then derive and contrast lower bounds on the regret of bandit algorithms satisfying these definitions. We show that for all of them, the learner's regret is increased by a multiplicative factor dependent on the privacy level $\epsilon$, but that the dependency is weaker when we do not require local differential privacy for the rewards.
* 15 pages, 1 figure, 9 theorems
View paper on