 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialect Diversity in Text Summarization on Twitter
Paper and Code
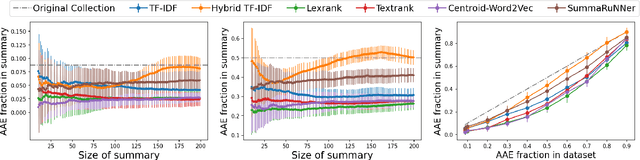
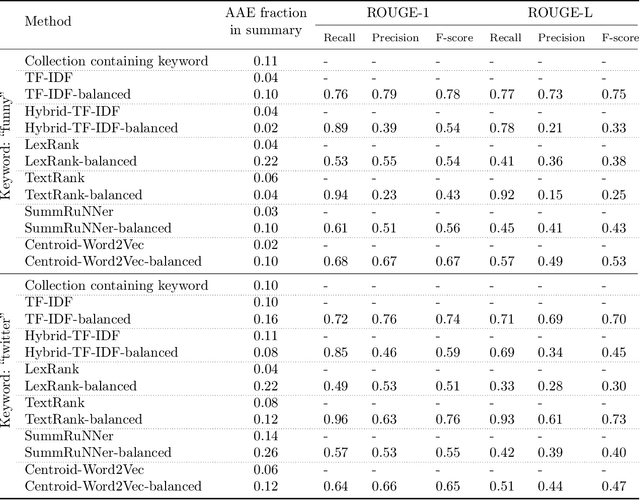
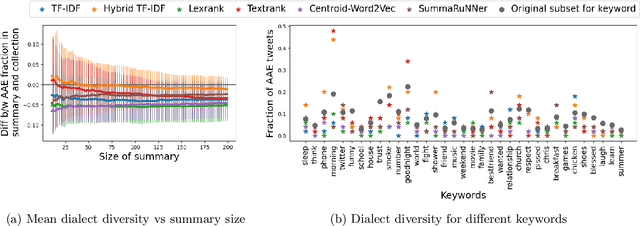
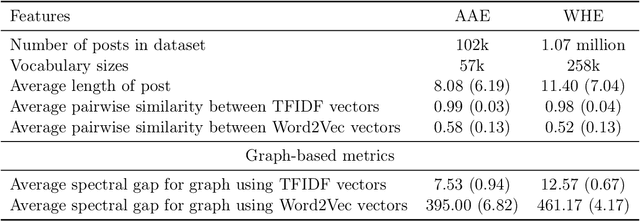
Extractive summarization algorithms can be used on Twitter data to return a set of posts that succinctly capture a topic. However, Twitter datasets have a significant fraction of posts written in different English dialects. We study the dialect bias in the summaries of such datasets generated by common summarization algorithms and observe that, for datasets that have sentences from more than one dialect, most summarization algorithms return summaries that under-represent the minority dialect. To correct for this bias, we propose a framework that takes an existing summarization algorithm as a blackbox and, using a small set of dialect-diverse sentences, returns a summary that is relatively more dialect-diverse. Crucially, our approach does not need the sentences in the dataset to have dialect labels, ensuring that the diversification process is independent of dialect classification and language identification models. We show the efficacy of our approach on Twitter datasets containing posts written in dialects used by different social groups defined by race, region or gender; in all cases, our approach leads to improved dialect diversity compared to the standard summarization approaches.