Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Mitigation of Rare Subclasses in Neural Network Classifiers
Paper and Code
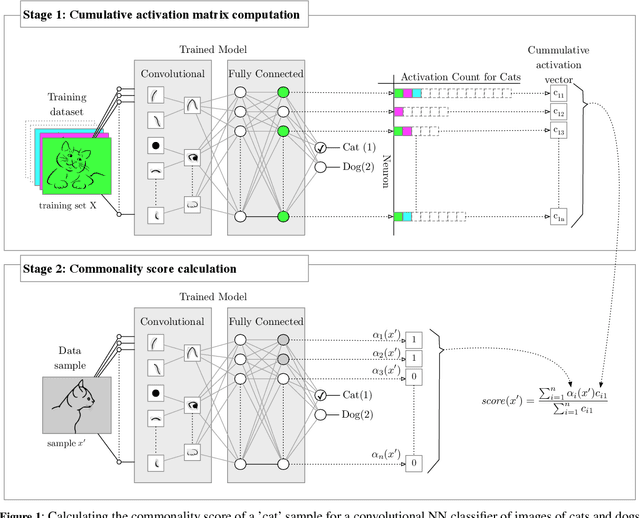
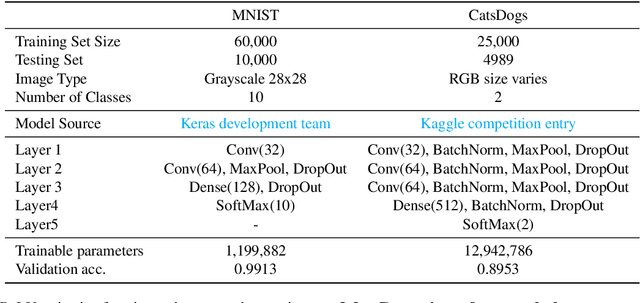
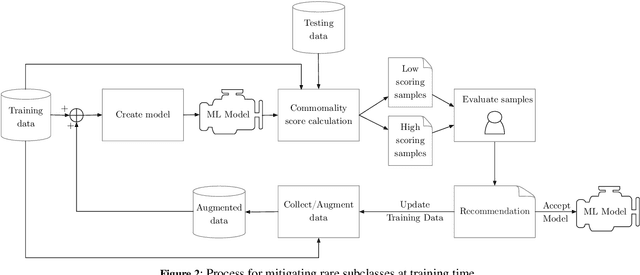

Regions of high-dimensional input spaces that are underrepresented in training datasets reduce machine-learnt classifier performance, and may lead to corner cases and unwanted bias for classifiers used in decision making systems. When these regions belong to otherwise well-represented classes, their presence and negative impact are very hard to identify. We propose an approach for the detection and mitigation of such rare subclasses in neural network classifiers. The new approach is underpinned by an easy-to-compute commonality metric that supports the detection of rare subclasses, and comprises methods for reducing their impact during both model training and model exploitation.
* 12 pages, 11 Figures, 4 Tables
View paper on