Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting the Most Unusual Part of Two and Three-dimensional Digital Images
Paper and Code
May 05, 2010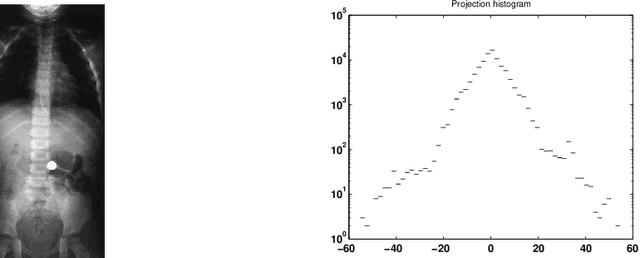
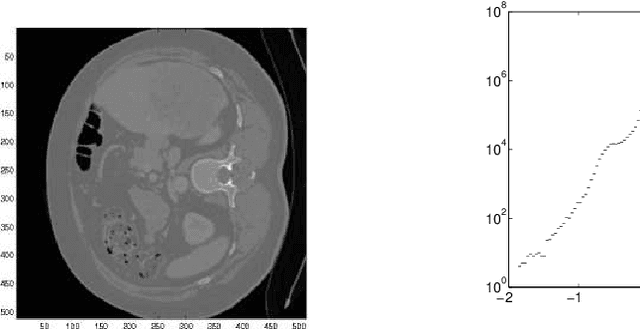


The purpose of this paper is to introduce an algorithm that can detect the most unusual part of a digital image in probabilistic setting. The most unusual part of a given shape is defined as a part of the image that has the maximal distance to all non intersecting shapes with the same form. The method is tested on two and three-dimensional images and has shown very good results without any predefined model. A version of the method independent of the contrast of the image is considered and is found to be useful for finding the most unusual part (and the most similar part) of the image conditioned on given image. The results can be used to scan large image databases, as for example medical databases.
* Pattern Recognition 42(8): 1684-1692 (2009) * 16 pages
View paper on