Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Entities in the Astrophysics Literature: A Comparison of Word-based and Span-based Entity Recognition Methods
Paper and Code
Nov 24, 2022
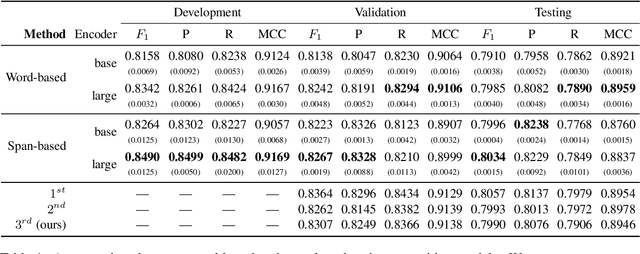
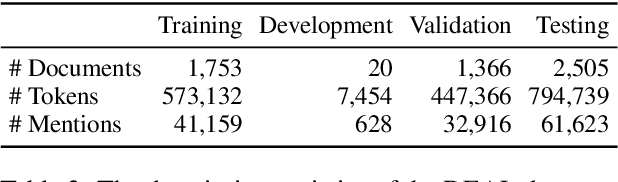

Information Extraction from scientific literature can be challenging due to the highly specialised nature of such text. We describe our entity recognition methods developed as part of the DEAL (Detecting Entities in the Astrophysics Literature) shared task. The aim of the task is to build a system that can identify Named Entities in a dataset composed by scholarly articles from astrophysics literature. We planned our participation such that it enables us to conduct an empirical comparison between word-based tagging and span-based classification methods. When evaluated on two hidden test sets provided by the organizer, our best-performing submission achieved $F_1$ scores of 0.8307 (validation phase) and 0.7990 (testing phase).
* AACL-IJCNLP Workshop on Information Extraction from Scientific
Publications (WIESP 2022)
View paper on