 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dependencies in Sparse, Multivariate Databases Using Probabilistic Programming and Non-parametric Bayes
Paper and Code
Mar 27, 2017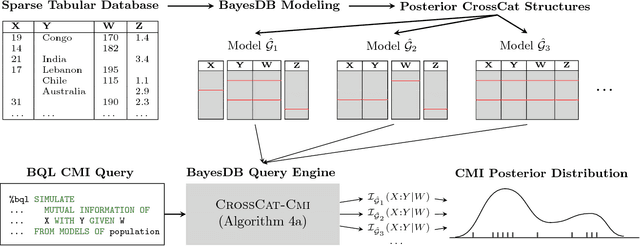
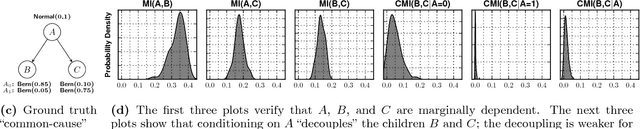


Datasets with hundreds of variables and many missing values are commonplace. In this setting, it is both statistically and computationally challenging to detect true predictive relationships between variables and also to suppress false positives. This paper proposes an approach that combines probabilistic programming, information theory, and non-parametric Bayes. It shows how to use Bayesian non-parametric modeling to (i) build an ensemble of joint probability models for all the variables; (ii) efficiently detect marginal independencies; and (iii) estimate the conditional mutual information between arbitrary subsets of variables, subject to a broad class of constraints. Users can access these capabilities using BayesDB, a probabilistic programming platform for probabilistic data analysis, by writing queries in a simple, SQL-like language. This paper demonstrates empirically that the method can (i) detect context-specific (in)dependencies on challenging synthetic problems and (ii) yield improved sensitivity and specificity over baselines from statistics and machine learning, on a real-world database of over 300 sparsely observed indicators of macroeconomic development and public health.