 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetail-Preserving Transformer for Light Field Image Super-Resolution
Paper and Code
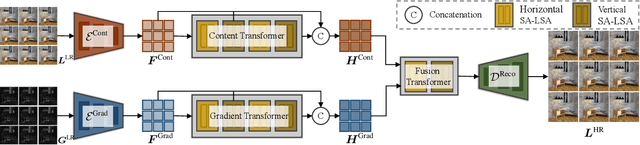
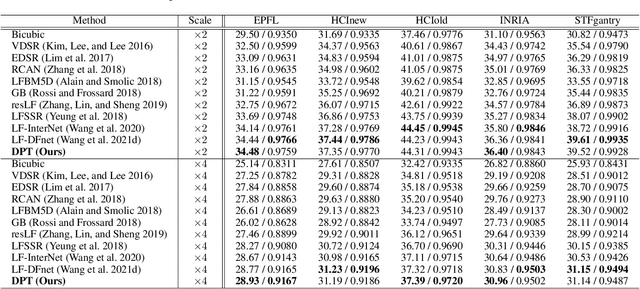
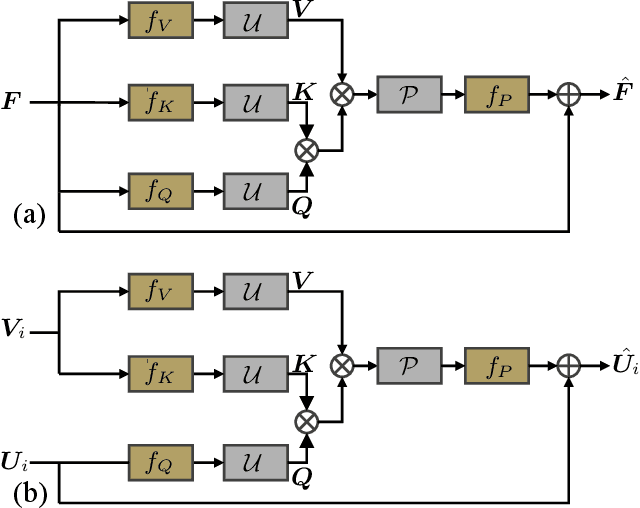
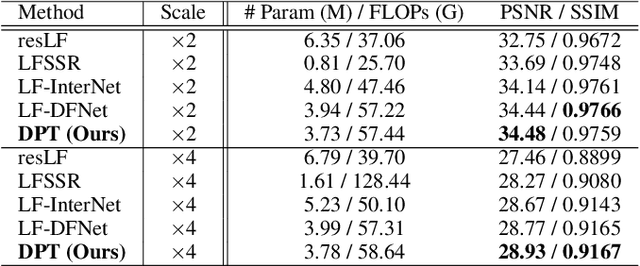
Recently, numerous algorithms have been developed to tackle the problem of light field super-resolution (LFSR), i.e., super-resolving low-resolution light fields to gain high-resolution views. Despite delivering encouraging results, these approaches are all convolution-based, and are naturally weak in global relation modeling of sub-aperture images necessarily to characterize the inherent structure of light fields. In this paper, we put forth a novel formulation built upon Transformers, by treating LFSR as a sequence-to-sequence reconstruction task. In particular, our model regards sub-aperture images of each vertical or horizontal angular view as a sequence, and establishes long-range geometric dependencies within each sequence via a spatial-angular locally-enhanced self-attention layer, which maintains the locality of each sub-aperture image as well. Additionally, to better recover image details, we propose a detail-preserving Transformer (termed as DPT), by leveraging gradient maps of light field to guide the sequence learning. DPT consists of two branches, with each associated with a Transformer for learning from an original or gradient image sequence. The two branches are finally fused to obtain comprehensive feature representations for reconstruction. Evaluations are conducted on a number of light field datasets, including real-world scenes and synthetic data. The proposed method achieves superior performance comparing with other state-of-the-art schemes. Our code is publicly available at: https://github.com/BITszwang/DPT.