 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescriptive vs. inferential community detection: pitfalls, myths and half-truths
Paper and Code
Dec 08, 2021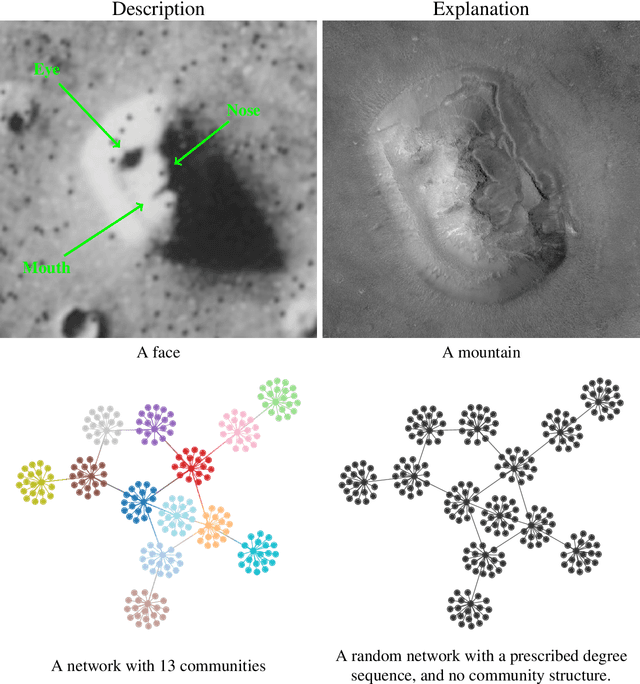
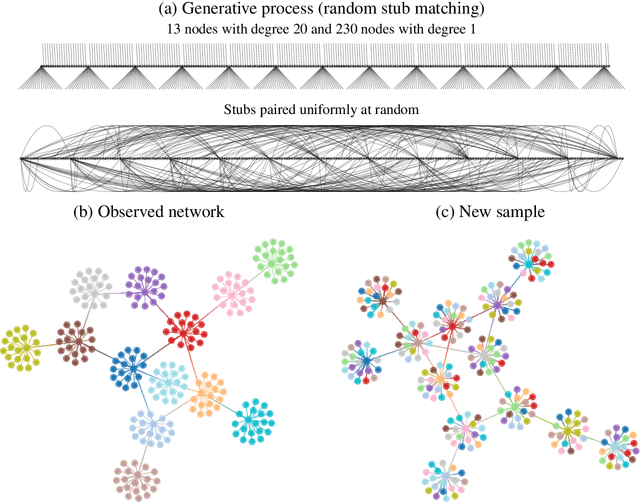
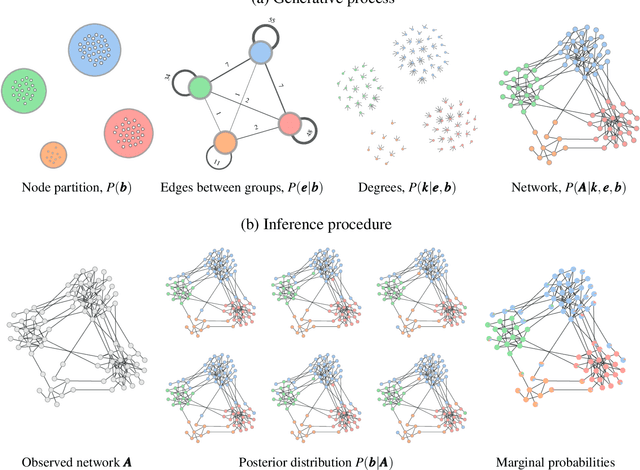

Community detection is one of the most important methodological fields of network science, and one which has attracted a significant amount of attention over the past decades. This area deals with the automated division of a network into fundamental building blocks, with the objective of providing a summary of its large-scale structure. Despite its importance and widespread adoption, there is a noticeable gap between what is considered the state-of-the-art and the methods that are actually used in practice in a variety of fields. Here we attempt to address this discrepancy by dividing existing methods according to whether they have a "descriptive" or an "inferential" goal. While descriptive methods find patterns in networks based on intuitive notions of community structure, inferential methods articulate a precise generative model, and attempt to fit it to data. In this way, they are able to provide insights into the mechanisms of network formation, and separate structure from randomness in a manner supported by statistical evidence. We review how employing descriptive methods with inferential aims is riddled with pitfalls and misleading answers, and thus should be in general avoided. We argue that inferential methods are more typically aligned with clearer scientific questions, yield more robust results, and should be in many cases preferred. We attempt to dispel some myths and half-truths often believed when community detection is employed in practice, in an effort to improve both the use of such methods as well as the interpretation of their results.