 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeRDaVa: Deletion-Robust Data Valuation for Machine Learning
Paper and Code


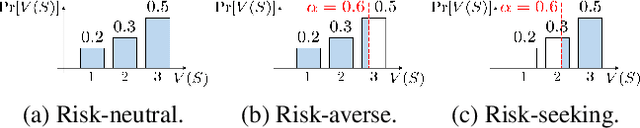
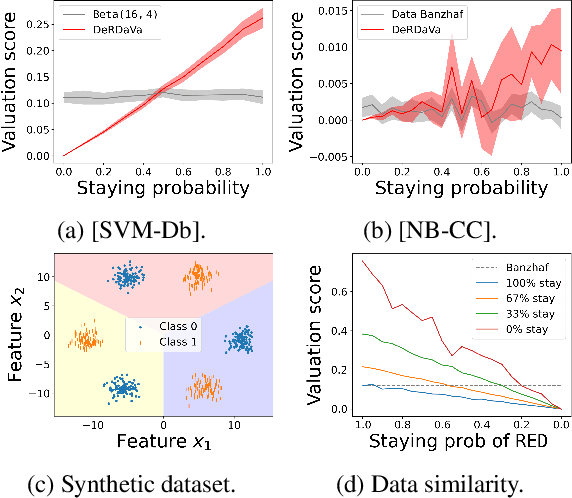
Data valuation is concerned with determining a fair valuation of data from data sources to compensate them or to identify training examples that are the most or least useful for predictions. With the rising interest in personal data ownership and data protection regulations, model owners will likely have to fulfil more data deletion requests. This raises issues that have not been addressed by existing works: Are the data valuation scores still fair with deletions? Must the scores be expensively recomputed? The answer is no. To avoid recomputations, we propose using our data valuation framework DeRDaVa upfront for valuing each data source's contribution to preserving robust model performance after anticipated data deletions. DeRDaVa can be efficiently approximated and will assign higher values to data that are more useful or less likely to be deleted. We further generalize DeRDaVa to Risk-DeRDaVa to cater to risk-averse/seeking model owners who are concerned with the worst/best-cases model utility. We also empirically demonstrate the practicality of our solutions.