 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Enables Long-Term Memory for Recurrent Neural Networks
Paper and Code
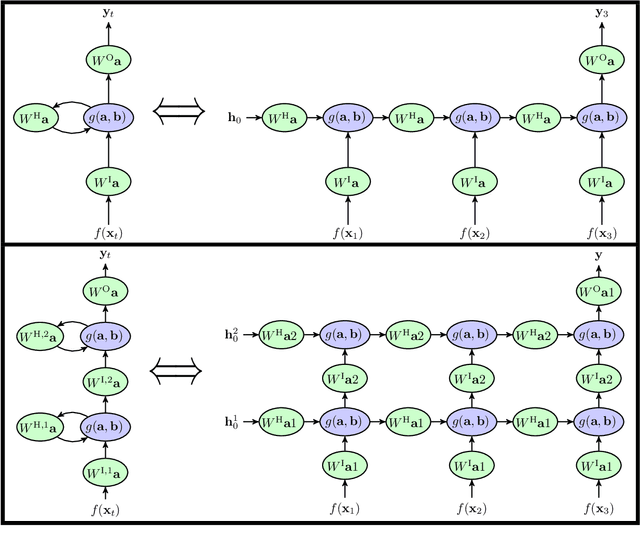
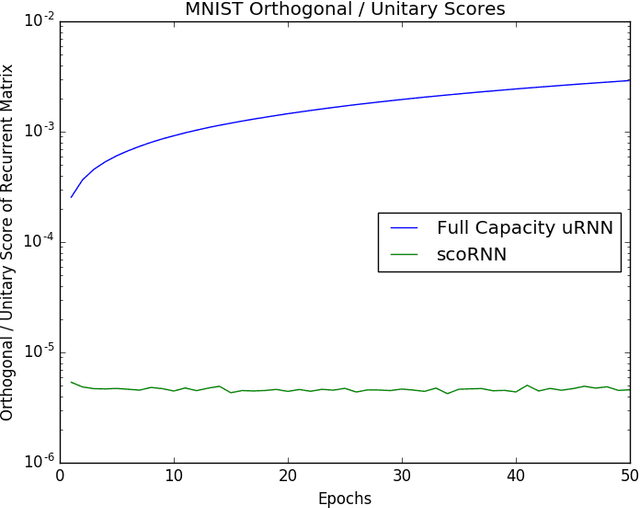
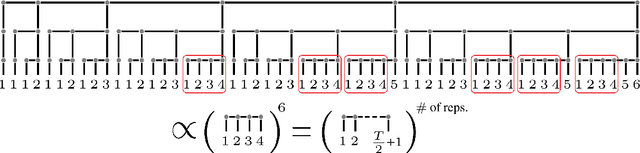
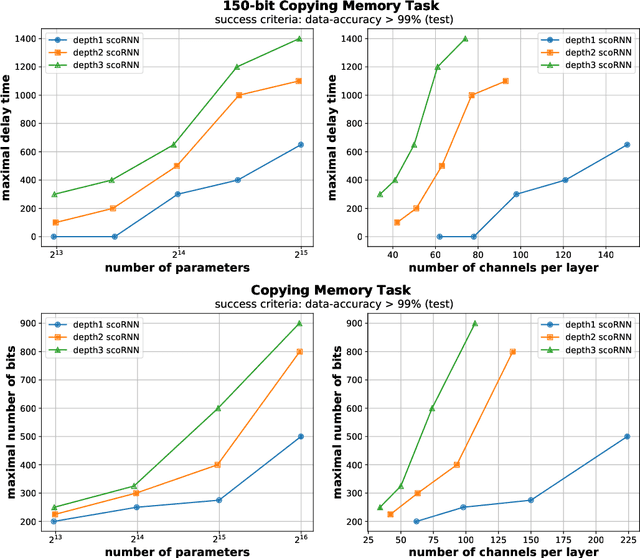
A key attribute that drives the unprecedented success of modern Recurrent Neural Networks (RNNs) on learning tasks which involve sequential data, is their ability to model intricate long-term temporal dependencies. However, a well established measure of RNNs long-term memory capacity is lacking, and thus formal understanding of the effect of depth on their ability to correlate data throughout time is limited. Specifically, existing depth efficiency results on convolutional networks do not suffice in order to account for the success of deep RNNs on data of varying lengths. In order to address this, we introduce a measure of the network's ability to support information flow across time, referred to as the Start-End separation rank, which reflects the distance of the function realized by the recurrent network from modeling no dependency between the beginning and end of the input sequence. We prove that deep recurrent networks support Start-End separation ranks which are combinatorially higher than those supported by their shallow counterparts. Thus, we establish that depth brings forth an overwhelming advantage in the ability of recurrent networks to model long-term dependencies, and provide an exemplar of quantifying this key attribute. We empirically demonstrate the discussed phenomena on common RNNs through extensive experimental evaluation using the optimization technique of restricting the hidden-to-hidden matrix to being orthogonal. Finally, we employ the tool of quantum Tensor Networks to gain additional graphic insights regarding the complexity brought forth by depth in recurrent networks.