Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth and nonlinearity induce implicit exploration for RL
Paper and Code
May 29, 2018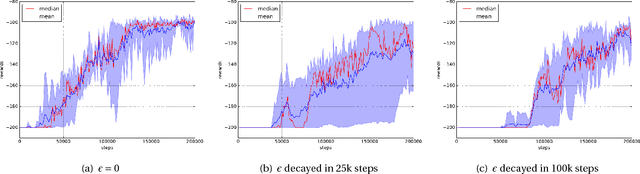
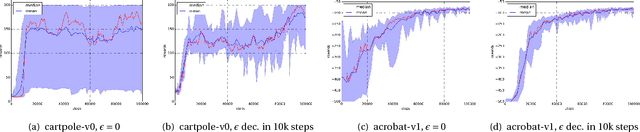
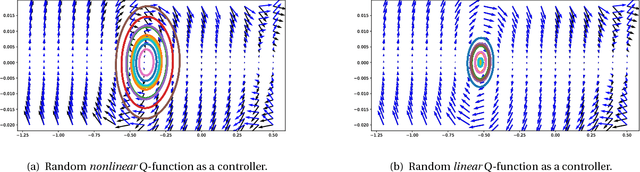
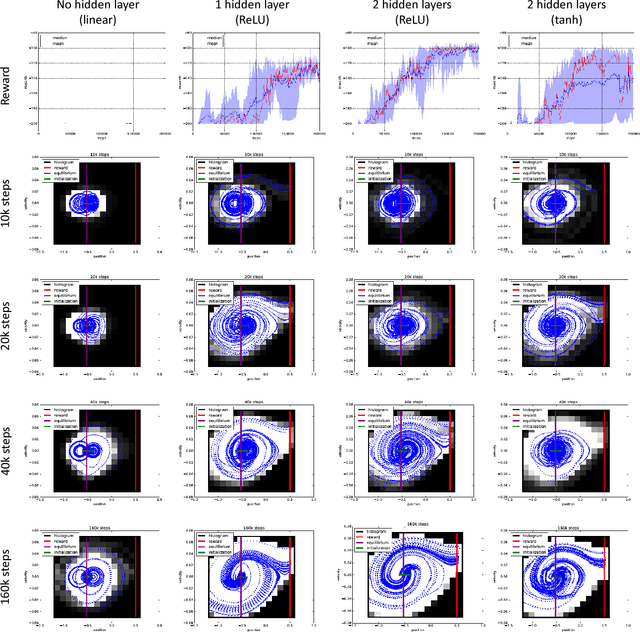
The question of how to explore, i.e., take actions with uncertain outcomes to learn about possible future rewards, is a key question in reinforcement learning (RL). Here, we show a surprising result: We show that Q-learning with nonlinear Q-function and no explicit exploration (i.e., a purely greedy policy) can learn several standard benchmark tasks, including mountain car, equally well as, or better than, the most commonly-used $\epsilon$-greedy exploration. We carefully examine this result and show that both the depth of the Q-network and the type of nonlinearity are important to induce such deterministic exploration.
View paper on