 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDENT-DDSP: Data-efficient noisy speech generator using differentiable digital signal processors for explicit distortion modelling and noise-robust speech recognition
Paper and Code
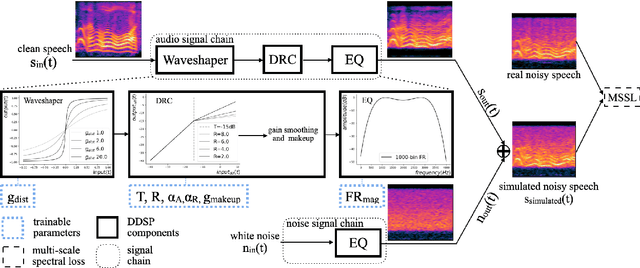
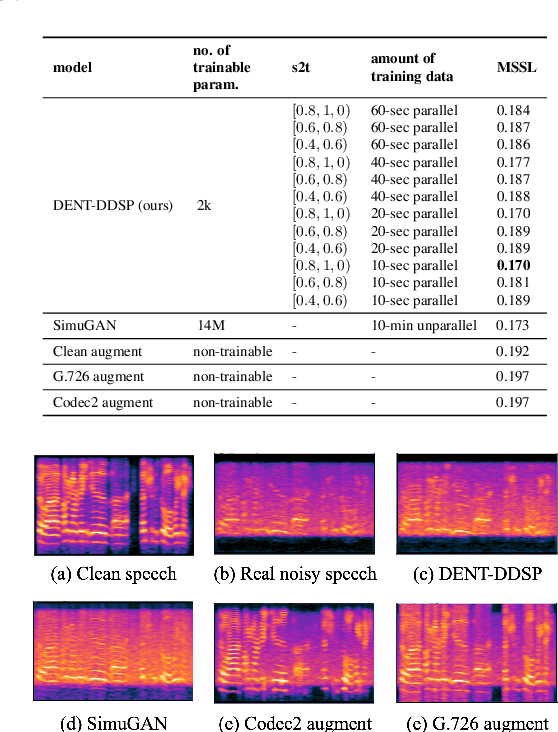
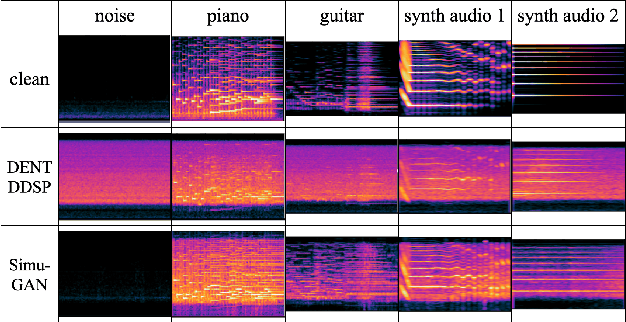
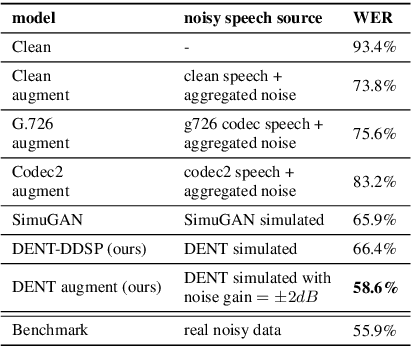
The performances of automatic speech recognition (ASR) systems degrade drastically under noisy conditions. Explicit distortion modelling (EDM), as a feature compensation step, is able to enhance ASR systems under such conditions by simulating the in-domain noisy speeches from the clean counterparts. Yet, existing distortion models are either non-trainable or unexplainable and often lack controllability and generalization ability. In this paper, we propose a fully explainable and controllable model: DENT-DDSP to achieve EDM. DENT-DDSP utilizes novel differentiable digital signal processing (DDSP) components and requires only 10 seconds of training data to achieve high fidelity. The experiment shows that the simulated noisy data from DENT-DDSP achieves the highest simulation fidelity compared to other baseline models in terms of multi-scale spectral loss (MSSL). Moreover, to validate whether the data simulated by DENT-DDSP are able to replace the scarce in-domain noisy data in the noise-robust ASR tasks, several downstream ASR models with the same architecture are trained using the simulated data and the real data. The experiment shows that the model trained with the simulated noisy data from DENT-DDSP achieves similar performances to the benchmark with a 2.7\% difference in terms of word error rate (WER). The code of the model is released online.