Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense-Captioning Events in Videos: SYSU Submission to ActivityNet Challenge 2020
Paper and Code
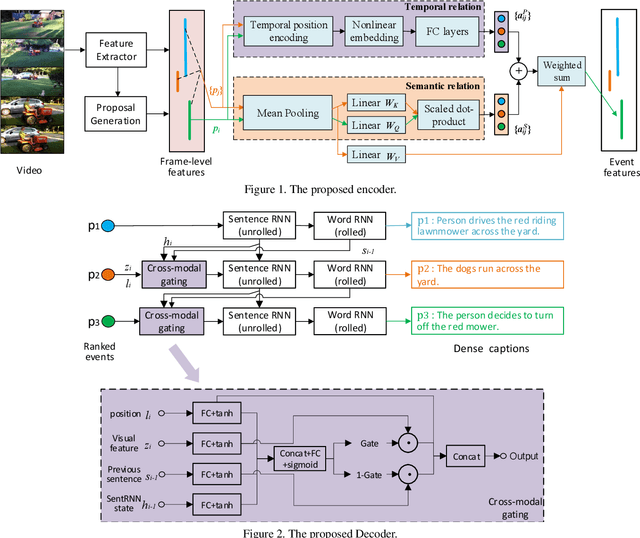
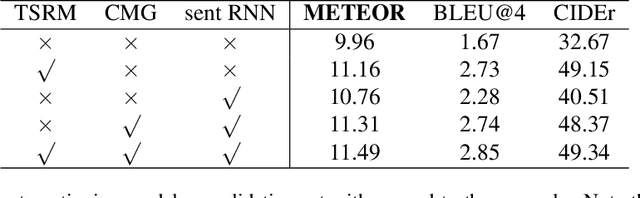

This technical report presents a brief description of our submission to the dense video captioning task of ActivityNet Challenge 2020. Our approach follows a two-stage pipeline: first, we extract a set of temporal event proposals; then we propose a multi-event captioning model to capture the event-level temporal relationships and effectively fuse the multi-modal information. Our approach achieves a 9.28 METEOR score on the test set.
* technical report, 4 pages, 2 figures
View paper on