 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratizing Production-Scale Distributed Deep Learning
Paper and Code
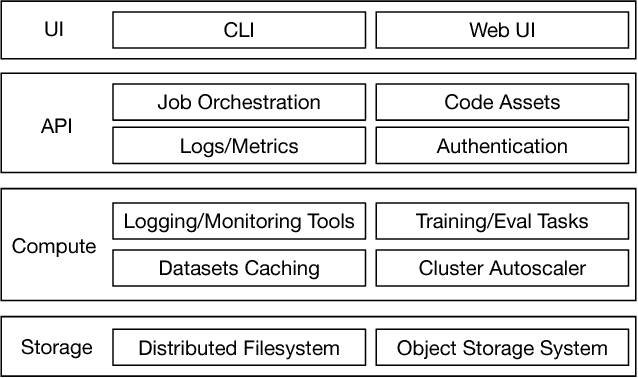
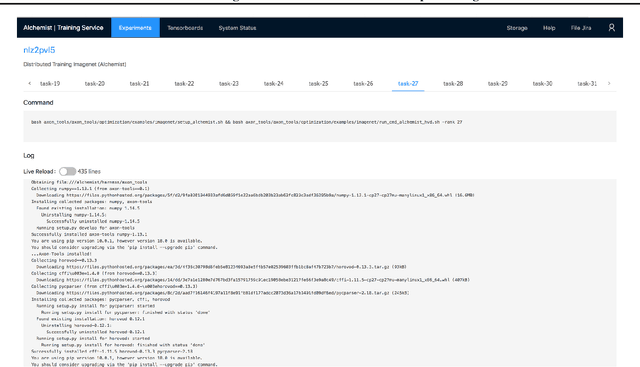
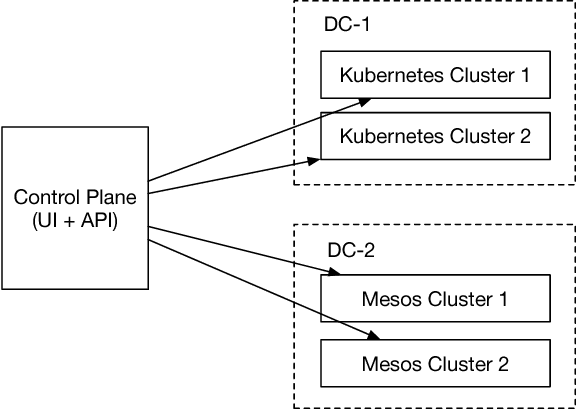
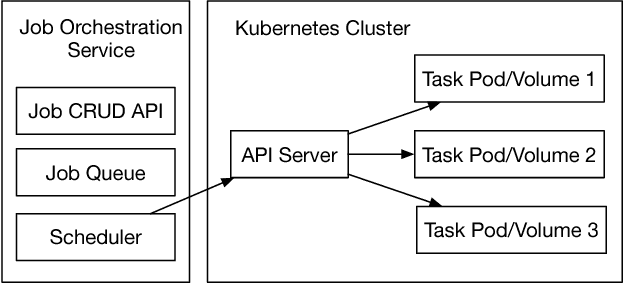
The interest and demand for training deep neural networks have been experiencing rapid growth, spanning a wide range of applications in both academia and industry. However, training them distributed and at scale remains difficult due to the complex ecosystem of tools and hardware involved. One consequence is that the responsibility of orchestrating these complex components is often left to one-off scripts and glue code customized for specific problems. To address these restrictions, we introduce \emph{Alchemist} - an internal service built at Apple from the ground up for \emph{easy}, \emph{fast}, and \emph{scalable} distributed training. We discuss its design, implementation, and examples of running different flavors of distributed training. We also present case studies of its internal adoption in the development of autonomous systems, where training times have been reduced by 10x to keep up with the ever-growing data collection.