 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta: A Cloud-assisted Data Enrichment Framework for On-Device Continual Learning
Paper and Code
Oct 24, 2024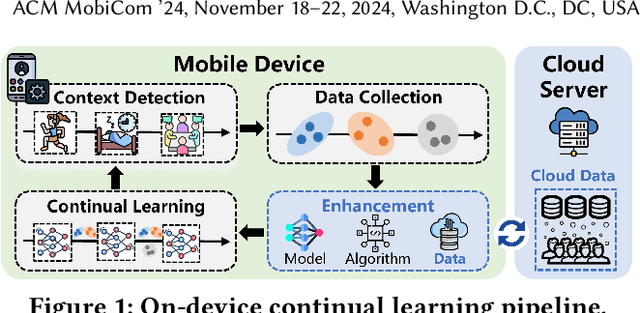

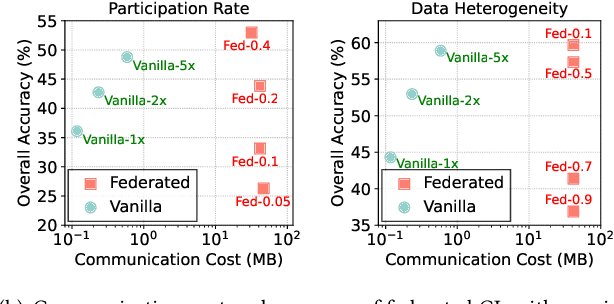

In modern mobile applications, users frequently encounter various new contexts, necessitating on-device continual learning (CL) to ensure consistent model performance. While existing research predominantly focused on developing lightweight CL frameworks, we identify that data scarcity is a critical bottleneck for on-device CL. In this work, we explore the potential of leveraging abundant cloud-side data to enrich scarce on-device data, and propose a private, efficient and effective data enrichment framework Delta. Specifically, Delta first introduces a directory dataset to decompose the data enrichment problem into device-side and cloud-side sub-problems without sharing sensitive data. Next, Delta proposes a soft data matching strategy to effectively solve the device-side sub-problem with sparse user data, and an optimal data sampling scheme for cloud server to retrieve the most suitable dataset for enrichment with low computational complexity. Further, Delta refines the data sampling scheme by jointly considering the impact of enriched data on both new and past contexts, mitigating the catastrophic forgetting issue from a new aspect. Comprehensive experiments across four typical mobile computing tasks with varied data modalities demonstrate that Delta could enhance the overall model accuracy by an average of 15.1%, 12.4%, 1.1% and 5.6% for visual, IMU, audio and textual tasks compared with few-shot CL, and consistently reduce the communication costs by over 90% compared to federated CL.