 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining an action of SO-rotations on images generated by projections of d-dimensional objects: Applications to pose inference with Geometric VAEs
Paper and Code
Jul 23, 2022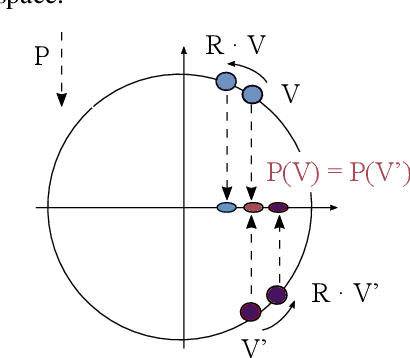
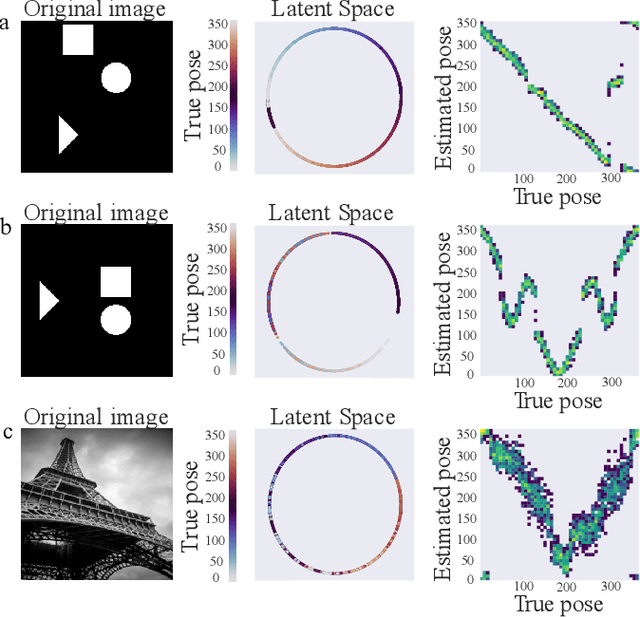
Recent advances in variational autoencoders (VAEs) have enabled learning latent manifolds as compact Lie groups, such as $SO(d)$. Since this approach assumes that data lies on a subspace that is homeomorphic to the Lie group itself, we here investigate how this assumption holds in the context of images that are generated by projecting a $d$-dimensional volume with unknown pose in $SO(d)$. Upon examining different theoretical candidates for the group and image space, we show that the attempt to define a group action on the data space generally fails, as it requires more specific geometric constraints on the volume. Using geometric VAEs, our experiments confirm that this constraint is key to proper pose inference, and we discuss the potential of these results for applications and future work.