 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Membership Inference Attacks via Privacy-aware Sparsity Tuning
Paper and Code
Oct 09, 2024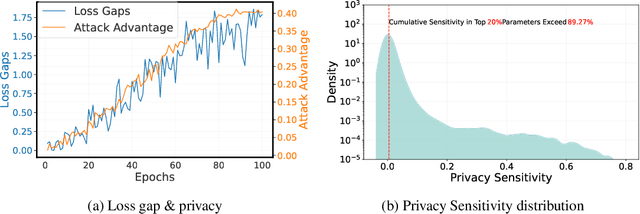
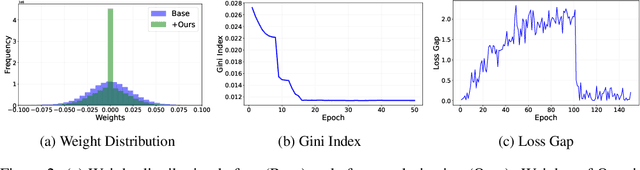
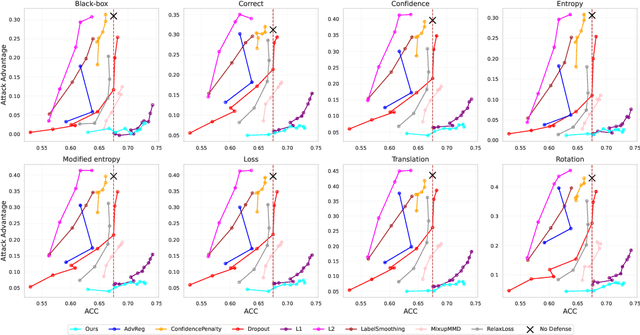
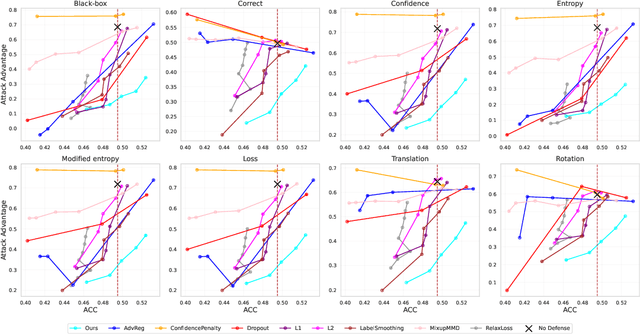
Over-parameterized models are typically vulnerable to membership inference attacks, which aim to determine whether a specific sample is included in the training of a given model. Previous Weight regularizations (e.g., L1 regularization) typically impose uniform penalties on all parameters, leading to a suboptimal tradeoff between model utility and privacy. In this work, we first show that only a small fraction of parameters substantially impact the privacy risk. In light of this, we propose Privacy-aware Sparsity Tuning (PAST), a simple fix to the L1 Regularization, by employing adaptive penalties to different parameters. Our key idea behind PAST is to promote sparsity in parameters that significantly contribute to privacy leakage. In particular, we construct the adaptive weight for each parameter based on its privacy sensitivity, i.e., the gradient of the loss gap with respect to the parameter. Using PAST, the network shrinks the loss gap between members and non-members, leading to strong resistance to privacy attacks. Extensive experiments demonstrate the superiority of PAST, achieving a state-of-the-art balance in the privacy-utility trade-off.