 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepHYDRA: Resource-Efficient Time-Series Anomaly Detection in Dynamically-Configured Systems
Paper and Code
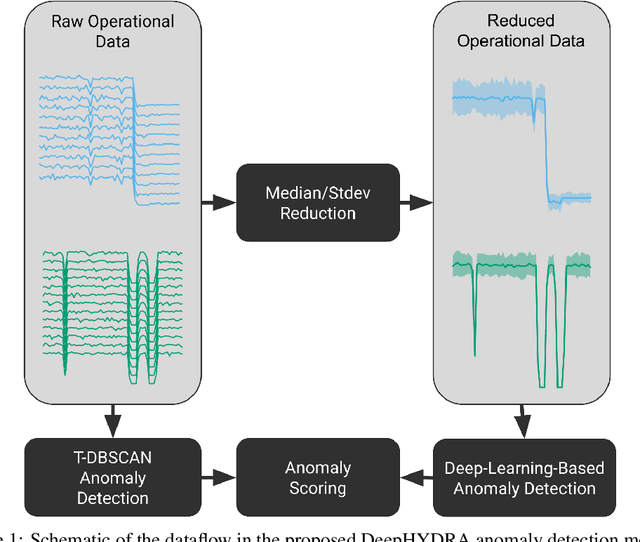

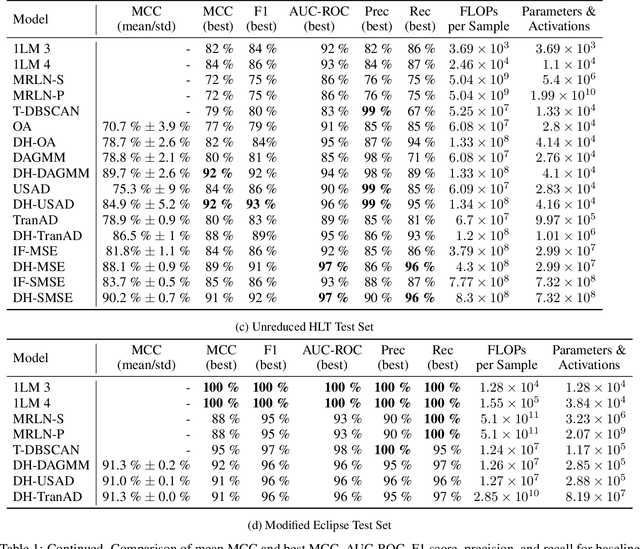
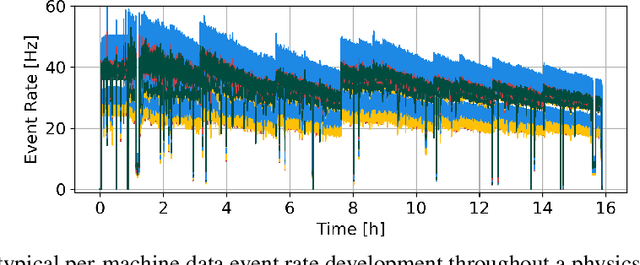
Anomaly detection in distributed systems such as High-Performance Computing (HPC) clusters is vital for early fault detection, performance optimisation, security monitoring, reliability in general but also operational insights. Deep Neural Networks have seen successful use in detecting long-term anomalies in multidimensional data, originating for instance from industrial or medical systems, or weather prediction. A downside of such methods is that they require a static input size, or lose data through cropping, sampling, or other dimensionality reduction methods, making deployment on systems with variability on monitored data channels, such as computing clusters difficult. To address these problems, we present DeepHYDRA (Deep Hybrid DBSCAN/Reduction-Based Anomaly Detection) which combines DBSCAN and learning-based anomaly detection. DBSCAN clustering is used to find point anomalies in time-series data, mitigating the risk of missing outliers through loss of information when reducing input data to a fixed number of channels. A deep learning-based time-series anomaly detection method is then applied to the reduced data in order to identify long-term outliers. This hybrid approach reduces the chances of missing anomalies that might be made indistinguishable from normal data by the reduction process, and likewise enables the algorithm to be scalable and tolerate partial system failures while retaining its detection capabilities. Using a subset of the well-known SMD dataset family, a modified variant of the Eclipse dataset, as well as an in-house dataset with a large variability in active data channels, made publicly available with this work, we furthermore analyse computational intensity, memory footprint, and activation counts. DeepHYDRA is shown to reliably detect different types of anomalies in both large and complex datasets.