 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepDIVA: A Highly-Functional Python Framework for Reproducible Experiments
Paper and Code
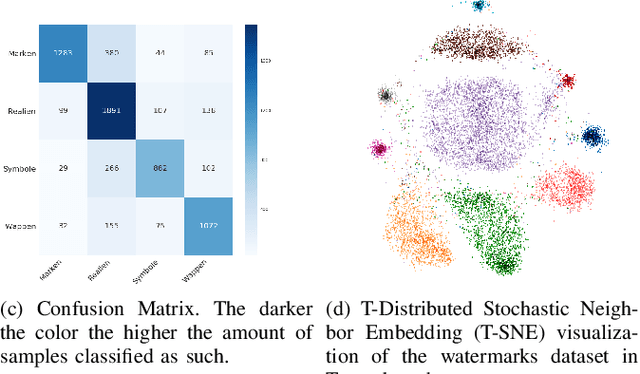
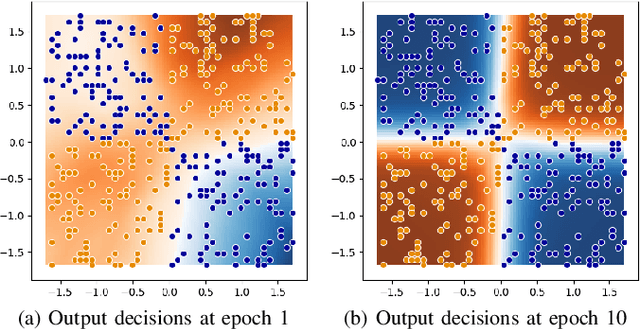
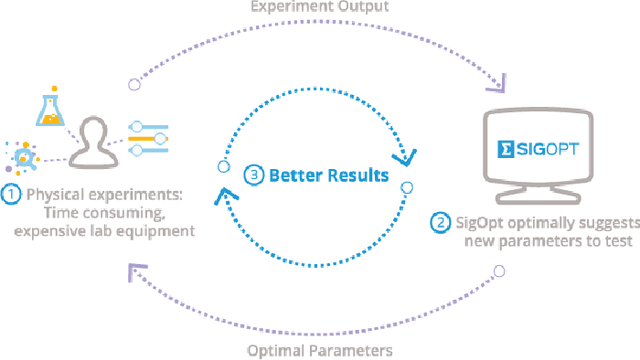
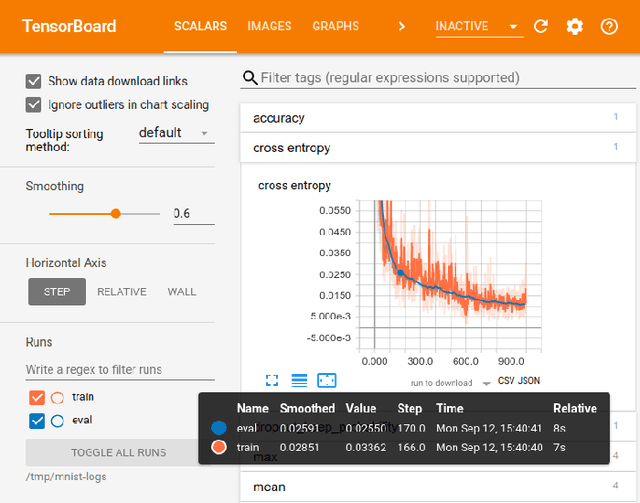
We introduce DeepDIVA: an infrastructure designed to enable quick and intuitive setup of reproducible experiments with a large range of useful analysis functionality. Reproducing scientific results can be a frustrating experience, not only in document image analysis but in machine learning in general. Using DeepDIVA a researcher can either reproduce a given experiment with a very limited amount of information or share their own experiments with others. Moreover, the framework offers a large range of functions, such as boilerplate code, keeping track of experiments, hyper-parameter optimization, and visualization of data and results. To demonstrate the effectiveness of this framework, this paper presents case studies in the area of handwritten document analysis where researchers benefit from the integrated functionality. DeepDIVA is implemented in Python and uses the deep learning framework PyTorch. It is completely open source, and accessible as Web Service through DIVAServices.