 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Scene Text Detection with Connected Component Proposals
Paper and Code
Aug 17, 2017

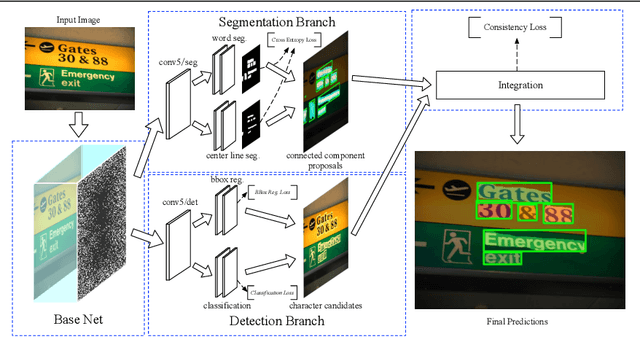
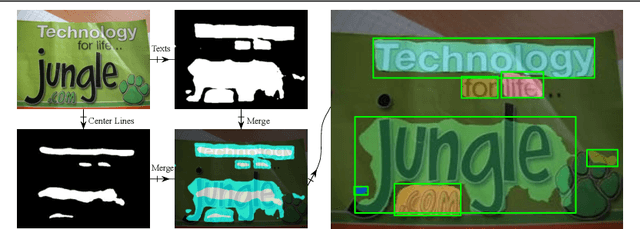
A growing demand for natural-scene text detection has been witnessed by the computer vision community since text information plays a significant role in scene understanding and image indexing. Deep neural networks are being used due to their strong capabilities of pixel-wise classification or word localization, similar to being used in common vision problems. In this paper, we present a novel two-task network with integrating bottom and top cues. The first task aims to predict a pixel-by-pixel labeling and based on which, word proposals are generated with a canonical connected component analysis. The second task aims to output a bundle of character candidates used later to verify the word proposals. The two sub-networks share base convolutional features and moreover, we present a new loss to strengthen the interaction between them. We evaluate the proposed network on public benchmark datasets and show it can detect arbitrary-orientation scene text with a finer output boundary. In ICDAR 2013 text localization task, we achieve the state-of-the-art performance with an F-score of 0.919 and a much better recall of 0.915.