Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Pepper: Expert Iteration based Chess agent in the Reinforcement Learning Setting
Paper and Code
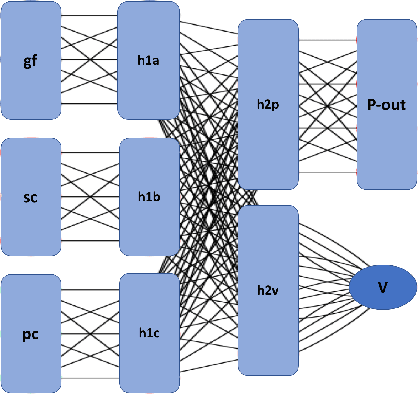
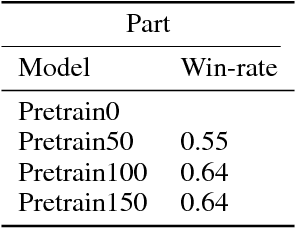
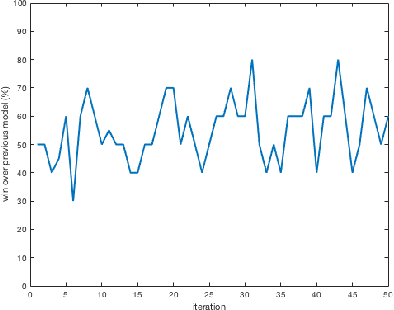
An almost-perfect chess playing agent has been a long standing challenge in the field of Artificial Intelligence. Some of the recent advances demonstrate we are approaching that goal. In this project, we provide methods for faster training of self-play style algorithms, mathematical details of the algorithm used, various potential future directions, and discuss most of the relevant work in the area of computer chess. Deep Pepper uses embedded knowledge to accelerate the training of the chess engine over a "tabula rasa" system such as Alpha Zero. We also release our code to promote further research.
* Tabula Rasa, Chess engine, Learning Fast and Slow, Reinforcement
Learning, Alpha Zero
View paper on