 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep NRSfM++: Towards 3D Reconstruction in the Wild
Paper and Code

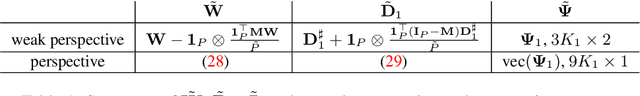
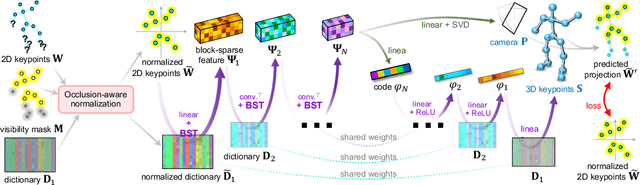

The recovery of 3D shape and pose solely from 2D landmarks stemming from a large ensemble of images can be viewed as a non-rigid structure from motion (NRSfM) problem. To date, however, the application of NRSfM to problems in the wild has been problematic. Classical NRSfM approaches do not scale to large numbers of images and can only handle certain types of 3D structure (e.g. low-rank). A recent breakthrough in this problem has allowed for the reconstruction of a substantially broader set of 3D structures, dramatically expanding the approach's importance to many problems in computer vision. However, the approach is still limited in that (i) it cannot handle missing/occluded points, and (ii) it is applicable only to weak-perspective camera models. In this paper, we present Deep NRSfM++, an approach to allow NRSfM to be truly applicable in the wild by offering up innovative solutions to the above two issues. Furthermore, we demonstrate state-of-the-art performance across numerous benchmarks, even against recent methods based on deep neural networks.