Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning model solves change point detection for multiple change types
Paper and Code

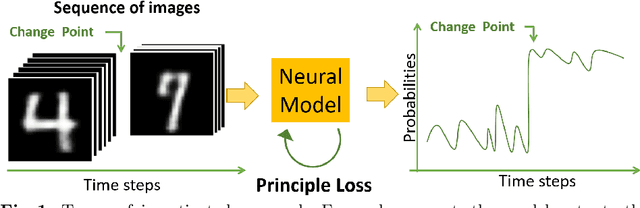

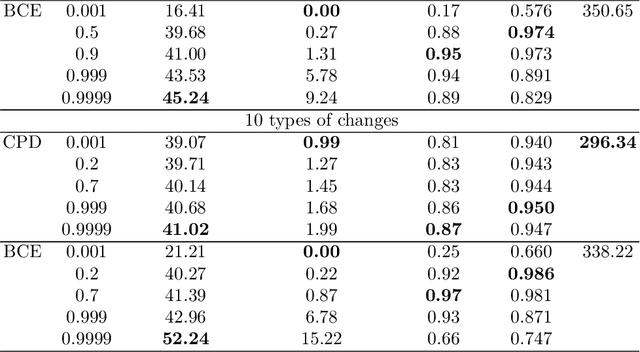
A change points detection aims to catch an abrupt disorder in data distribution. Common approaches assume that there are only two fixed distributions for data: one before and another after a change point. Real-world data are richer than this assumption. There can be multiple different distributions before and after a change. We propose an approach that works in the multiple-distributions scenario. Our approach learn representations for semi-structured data suitable for change point detection, while a common classifiers-based approach fails. Moreover, our model is more robust, when predicting change points. The datasets used for benchmarking are sequences of images with and without change points in them.
View paper on