Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning by Scattering
Paper and Code
Jun 25, 2015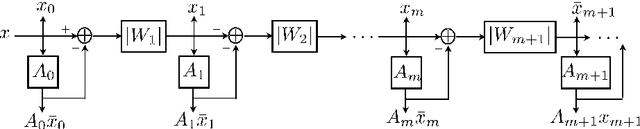
We introduce general scattering transforms as mathematical models of deep neural networks with l2 pooling. Scattering networks iteratively apply complex valued unitary operators, and the pooling is performed by a complex modulus. An expected scattering defines a contractive representation of a high-dimensional probability distribution, which preserves its mean-square norm. We show that unsupervised learning can be casted as an optimization of the space contraction to preserve the volume occupied by unlabeled examples, at each layer of the network. Supervised learning and classification are performed with an averaged scattering, which provides scattering estimations for multiple classes.
* 10 pages, 1 figure
View paper on