 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Learning Architectures for Multi-Pitch Estimation: Towards Reliable Evaluation
Paper and Code

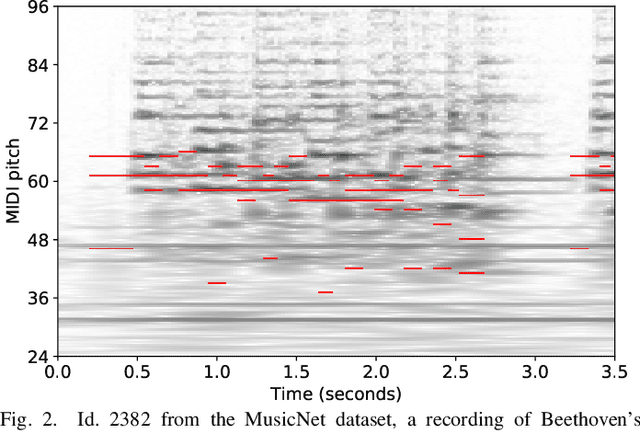


Extracting pitch information from music recordings is a challenging but important problem in music signal processing. Frame-wise transcription or multi-pitch estimation aims for detecting the simultaneous activity of pitches in polyphonic music recordings and has recently seen major improvements thanks to deep-learning techniques, with a variety of proposed network architectures. In this paper, we realize different architectures based on CNNs, the U-net structure, and self-attention components. We propose several modifications to these architectures including self-attention modules for skip connections, recurrent layers to replace the self-attention, and a multi-task strategy with simultaneous prediction of the degree of polyphony. We compare variants of these architectures in different sizes for multi-pitch estimation, focusing on Western classical music beyond the piano-solo scenario using the MusicNet and Schubert Winterreise datasets. Our experiments indicate that most architectures yield competitive results and that larger model variants seem to be beneficial. However, we find that these results substantially depend on randomization effects and the particular choice of the training-test split, which questions the claim of superiority for particular architectures given only small improvements. We therefore investigate the influence of dataset splits in the presence of several movements of a work cycle (cross-version evaluation) and propose a best-practice splitting strategy for MusicNet, which weakens the influence of individual test tracks and suppresses overfitting to specific works and recording conditions. A final evaluation on a mixed dataset suggests that improvements on one specific dataset do not necessarily generalize to other scenarios, thus emphasizing the need for further high-quality multi-pitch datasets in order to reliably measure progress in music transcription tasks.