 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Grokking: Would Deep Neural Networks Generalize Better?
Paper and Code
May 29, 2024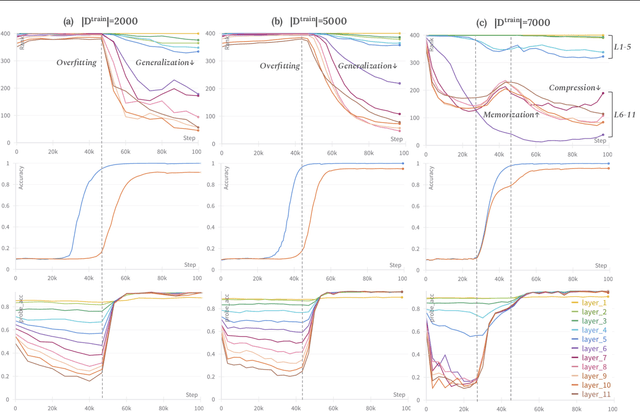



Recent research on the grokking phenomenon has illuminated the intricacies of neural networks' training dynamics and their generalization behaviors. Grokking refers to a sharp rise of the network's generalization accuracy on the test set, which occurs long after an extended overfitting phase, during which the network perfectly fits the training set. While the existing research primarily focus on shallow networks such as 2-layer MLP and 1-layer Transformer, we explore grokking on deep networks (e.g. 12-layer MLP). We empirically replicate the phenomenon and find that deep neural networks can be more susceptible to grokking than its shallower counterparts. Meanwhile, we observe an intriguing multi-stage generalization phenomenon when increase the depth of the MLP model where the test accuracy exhibits a secondary surge, which is scarcely seen on shallow models. We further uncover compelling correspondences between the decreasing of feature ranks and the phase transition from overfitting to the generalization stage during grokking. Additionally, we find that the multi-stage generalization phenomenon often aligns with a double-descent pattern in feature ranks. These observations suggest that internal feature rank could serve as a more promising indicator of the model's generalization behavior compared to the weight-norm. We believe our work is the first one to dive into grokking in deep neural networks, and investigate the relationship of feature rank and generalization performance.