 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Pronunciation and Prosody Modeling in Meta-Learning-Based Multilingual Speech Synthesis
Paper and Code
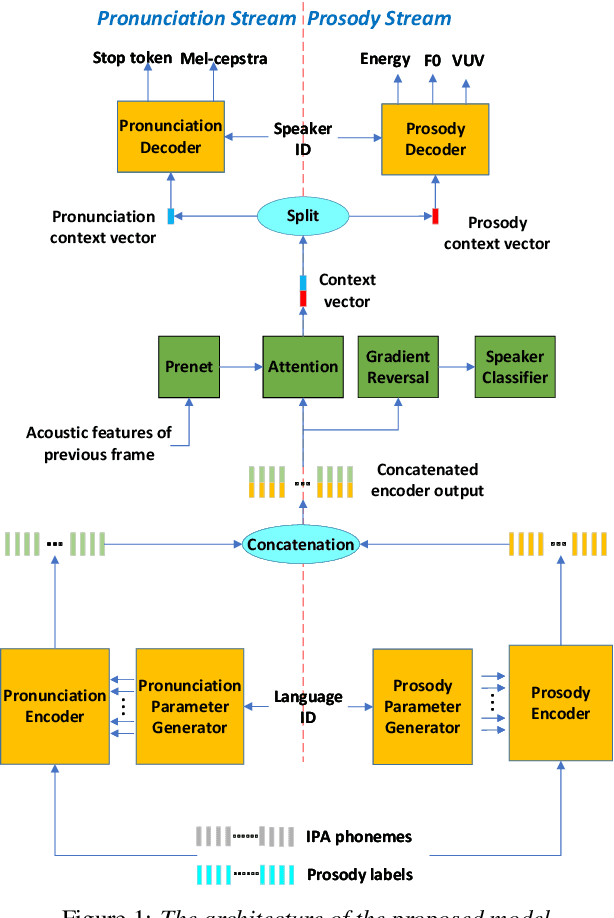

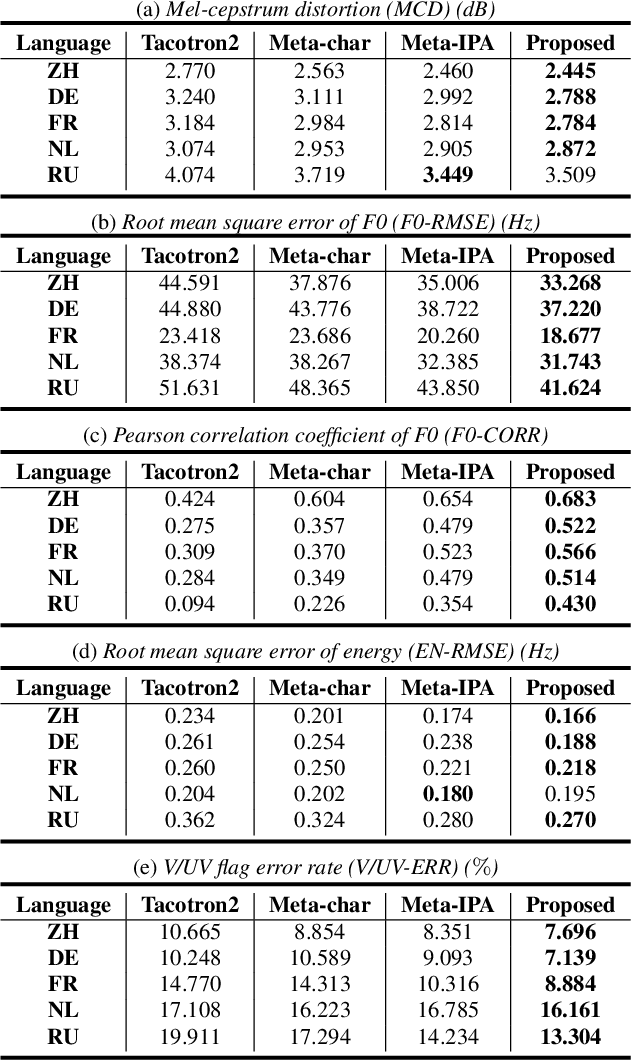
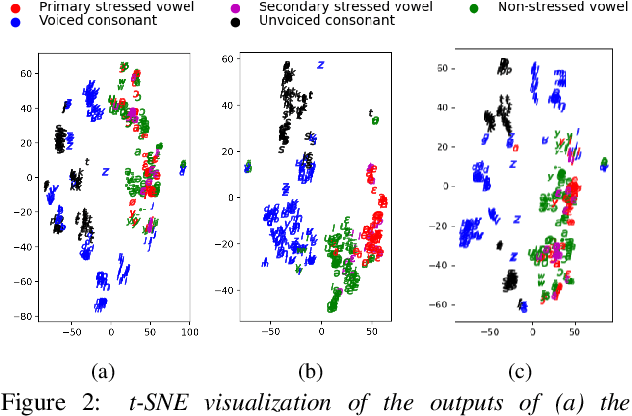
This paper presents a method of decoupled pronunciation and prosody modeling to improve the performance of meta-learning-based multilingual speech synthesis. The baseline meta-learning synthesis method adopts a single text encoder with a parameter generator conditioned on language embeddings and a single decoder to predict mel-spectrograms for all languages. In contrast, our proposed method designs a two-stream model structure that contains two encoders and two decoders for pronunciation and prosody modeling, respectively, considering that the pronunciation knowledge and the prosody knowledge should be shared in different ways among languages. In our experiments, our proposed method effectively improved the intelligibility and naturalness of multilingual speech synthesis comparing with the baseline meta-learning synthesis method.