 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Multi-Agent Reinforcement Learning for Task Offloading Under Uncertainty
Paper and Code
Jul 26, 2021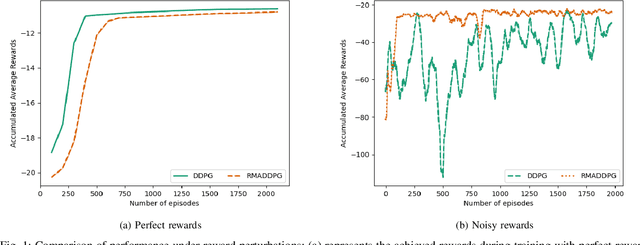
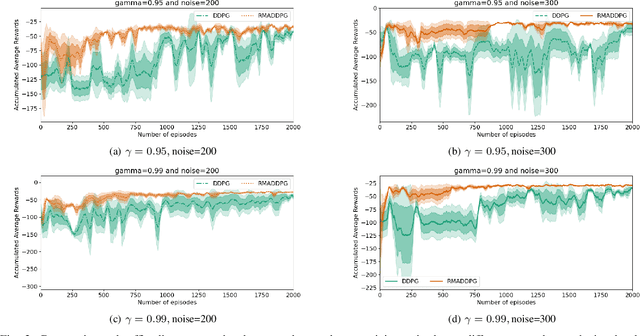
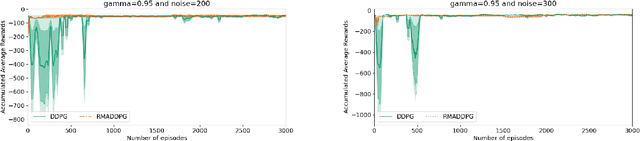
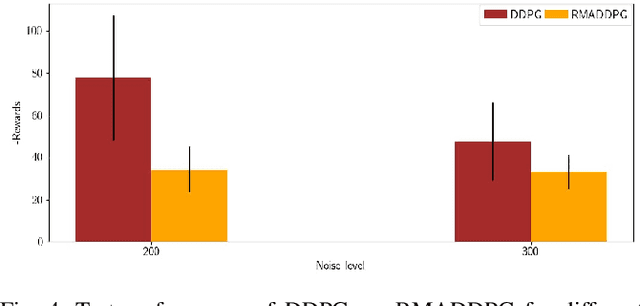
Multi-Agent Reinforcement Learning (MARL) is a challenging subarea of Reinforcement Learning due to the non-stationarity of the environments and the large dimensionality of the combined action space. Deep MARL algorithms have been applied to solve different task offloading problems. However, in real-world applications, information required by the agents (i.e. rewards and states) are subject to noise and alterations. The stability and the robustness of deep MARL to practical challenges is still an open research problem. In this work, we apply state-of-the art MARL algorithms to solve task offloading with reward uncertainty. We show that perturbations in the reward signal can induce decrease in the performance compared to learning with perfect rewards. We expect this paper to stimulate more research in studying and addressing the practical challenges of deploying deep MARL solutions in wireless communications systems.