 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion
Paper and Code

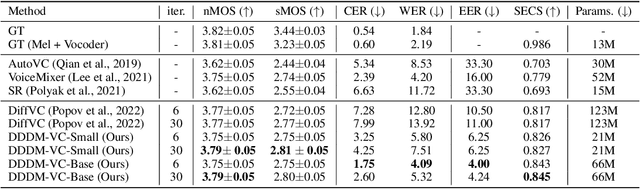

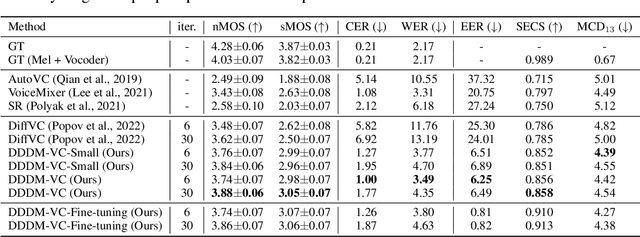
Diffusion-based generative models have exhibited powerful generative performance in recent years. However, as many attributes exist in the data distribution and owing to several limitations of sharing the model parameters across all levels of the generation process, it remains challenging to control specific styles for each attribute. To address the above problem, this paper presents decoupled denoising diffusion models (DDDMs) with disentangled representations, which can control the style for each attribute in generative models. We apply DDDMs to voice conversion (VC) tasks to address the challenges of disentangling and controlling each speech attribute (e.g., linguistic information, intonation, and timbre). First, we use a self-supervised representation to disentangle the speech representation. Subsequently, the DDDMs are applied to resynthesize the speech from the disentangled representations for denoising with respect to each attribute. Moreover, we also propose the prior mixup for robust voice style transfer, which uses the converted representation of the mixed style as a prior distribution for the diffusion models. The experimental results reveal that our method outperforms publicly available VC models. Furthermore, we show that our method provides robust generative performance regardless of the model size. Audio samples are available https://hayeong0.github.io/DDDM-VC-demo/.