Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset for Automatic Summarization of Russian News
Paper and Code

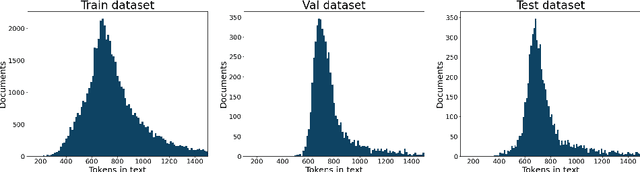

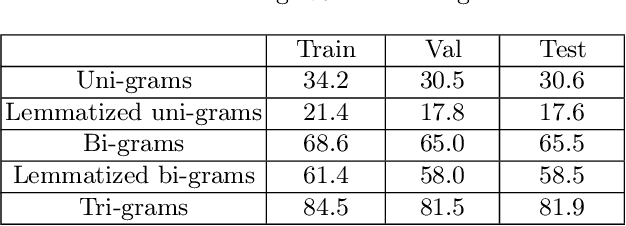
Automatic text summarization has been studied in a variety of domains and languages. However, this does not hold for the Russian language. To overcome this issue, we present Gazeta, the first dataset for summarization of Russian news. We describe the properties of this dataset and benchmark several extractive and abstractive models. We demonstrate that the dataset is a valid task for methods of text summarization for Russian. Additionally, we prove the pretrained mBART model to be useful for Russian text summarization.
* Accepted to AINL 2020
View paper on