Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Factory: A Toolchain For Generative Computer Vision Datasets
Paper and Code
Sep 20, 2023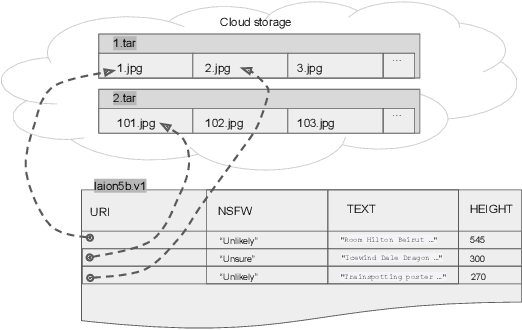

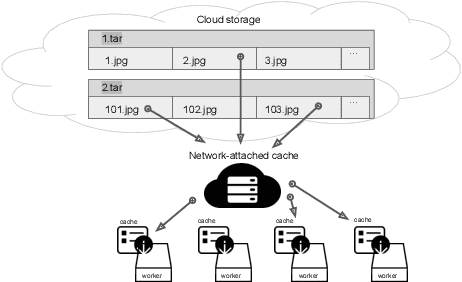
Generative AI workflows heavily rely on data-centric tasks - such as filtering samples by annotation fields, vector distances, or scores produced by custom classifiers. At the same time, computer vision datasets are quickly approaching petabyte volumes, rendering data wrangling difficult. In addition, the iterative nature of data preparation necessitates robust dataset sharing and versioning mechanisms, both of which are hard to implement ad-hoc. To solve these challenges, we propose a "dataset factory" approach that separates the storage and processing of samples from metadata and enables data-centric operations at scale for machine learning teams and individual researchers.
* Presented at the datacomp.ai workshop at ICCV 2023
View paper on