 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Smashing 2.0: Sequence Likelihood (SL) Divergence For Fast Time Series Comparison
Paper and Code
Oct 08, 2019
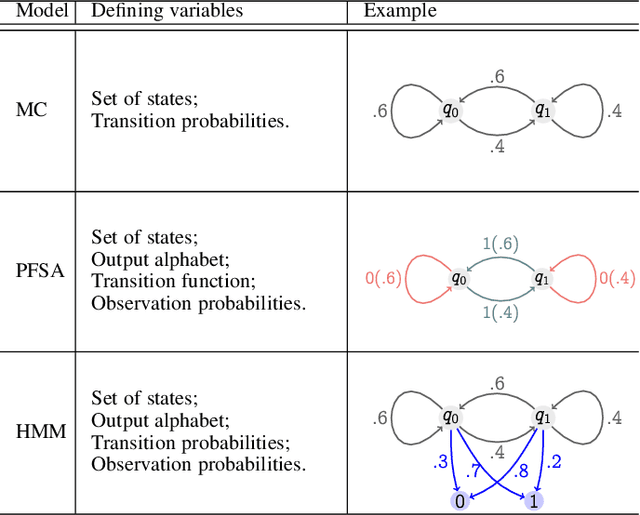
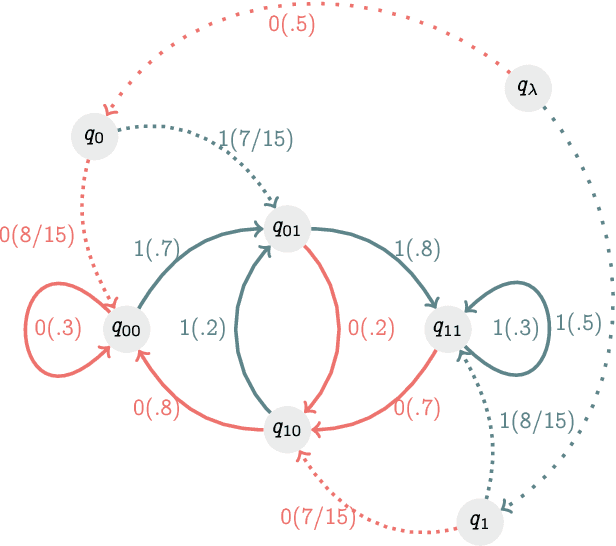

Recognizing subtle historical patterns is central to modeling and forecasting problems in time series analysis. Here we introduce and develop a new approach to quantify deviations in the underlying hidden generators of observed data streams, resulting in a new efficiently computable universal metric for time series. The proposed metric is in the sense that we can compare and contrast data streams regardless of where and how they are generated and without any feature engineering step. The approach proposed in this paper is conceptually distinct from our previous work on data smashing, and vastly improves discrimination performance and computing speed. The core idea here is the generalization of the notion of KL divergence often used to compare probability distributions to a notion of divergence in time series. We call this the sequence likelihood (SL) divergence, which may be used to measure deviations within a well-defined class of discrete-valued stochastic processes. We devise efficient estimators of SL divergence from finite sample paths and subsequently formulate a universal metric useful for computing distance between time series produced by hidden stochastic generators.