 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Antipatterns for Software Analytics
Paper and Code
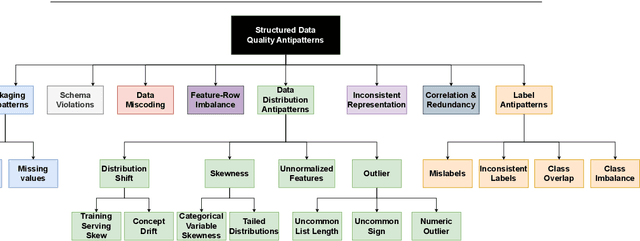
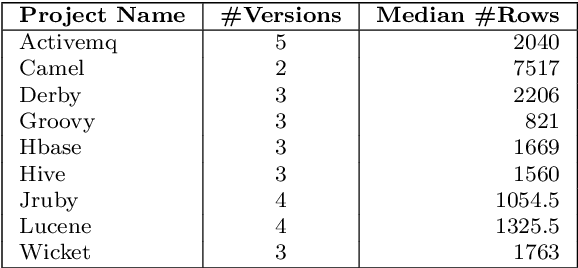
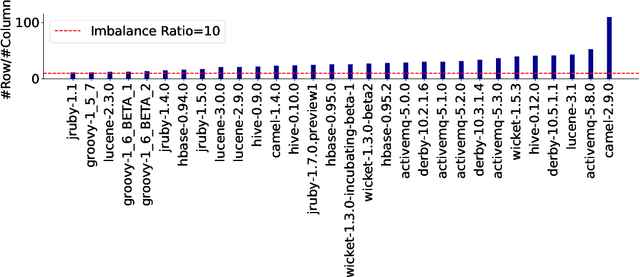
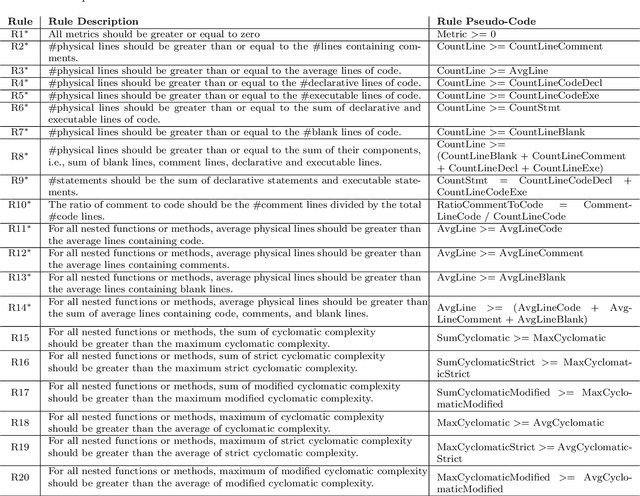
Background: Data quality is vital in software analytics, particularly for machine learning (ML) applications like software defect prediction (SDP). Despite the widespread use of ML in software engineering, the effect of data quality antipatterns on these models remains underexplored. Objective: This study develops a taxonomy of ML-specific data quality antipatterns and assesses their impact on software analytics models' performance and interpretation. Methods: We identified eight types and 14 sub-types of ML-specific data quality antipatterns through a literature review. We conducted experiments to determine the prevalence of these antipatterns in SDP data (RQ1), assess how cleaning order affects model performance (RQ2), evaluate the impact of antipattern removal on performance (RQ3), and examine the consistency of interpretation from models built with different antipatterns (RQ4). Results: In our SDP case study, we identified nine antipatterns. Over 90% of these overlapped at both row and column levels, complicating cleaning prioritization and risking excessive data removal. The order of cleaning significantly impacts ML model performance, with neural networks being more resilient to cleaning order changes than simpler models like logistic regression. Antipatterns such as Tailed Distributions and Class Overlap show a statistically significant correlation with performance metrics when other antipatterns are cleaned. Models built with different antipatterns showed moderate consistency in interpretation results. Conclusion: The cleaning order of different antipatterns impacts ML model performance. Five antipatterns have a statistically significant correlation with model performance when others are cleaned. Additionally, model interpretation is moderately affected by different data quality antipatterns.