 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Preprocessing to Mitigate Bias with Boosted Fair Mollifiers
Paper and Code
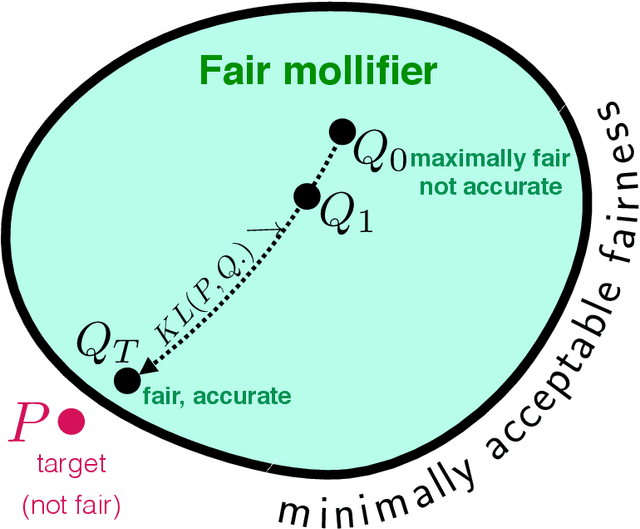
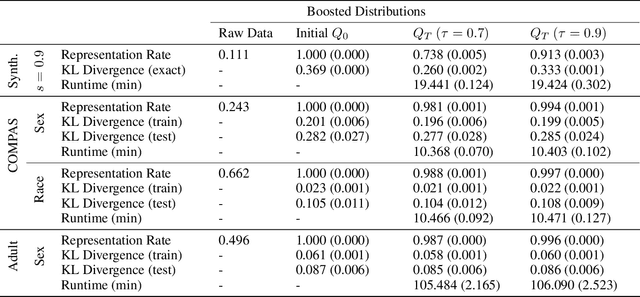
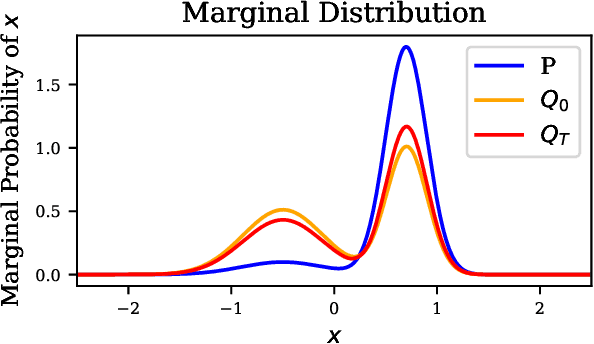

In a recent paper, Celis et al. (2020) introduced a new approach to fairness that corrects the data distribution itself. The approach is computationally appealing, but its approximation guarantees with respect to the target distribution can be quite loose as they need to rely on a (typically limited) number of constraints on data-based aggregated statistics; also resulting on a fairness guarantee which can be data dependent. Our paper makes use of a mathematical object recently introduced in privacy -- mollifiers of distributions -- and a popular approach to machine learning -- boosting -- to get an approach in the same lineage as Celis et al. but without those impediments, including in particular, better guarantees in terms of accuracy and finer guarantees in terms of fairness. The approach involves learning the sufficient statistics of an exponential family. When training data is tabular, it is defined by decision trees whose interpretability can provide clues on the source of (un)fairness. Experiments display the quality of the results obtained for simulated and real-world data.