 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData leakage in cross-modal retrieval training: A case study
Paper and Code
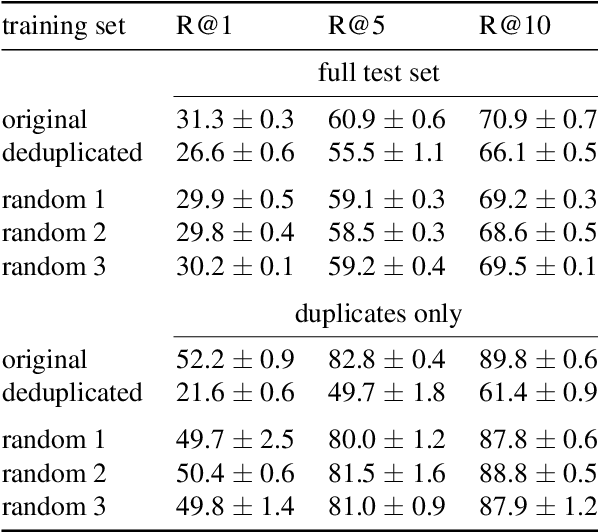
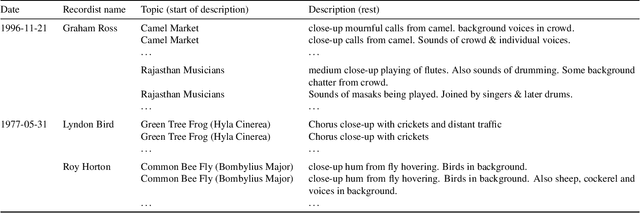
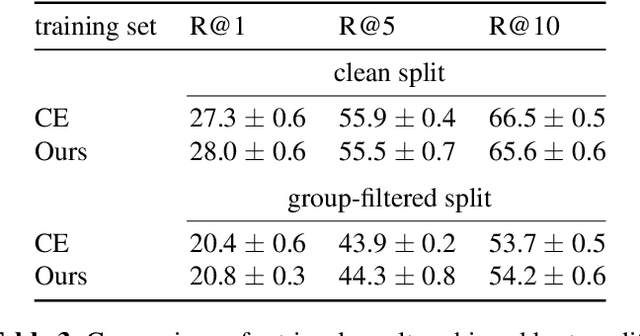
The recent progress in text-based audio retrieval was largely propelled by the release of suitable datasets. Since the manual creation of such datasets is a laborious task, obtaining data from online resources can be a cheap solution to create large-scale datasets. We study the recently proposed SoundDesc benchmark dataset, which was automatically sourced from the BBC Sound Effects web page. In our analysis, we find that SoundDesc contains several duplicates that cause leakage of training data to the evaluation data. This data leakage ultimately leads to overly optimistic retrieval performance estimates in previous benchmarks. We propose new training, validation, and testing splits for the dataset that we make available online. To avoid weak contamination of the test data, we pool audio files that share similar recording setups. In our experiments, we find that the new splits serve as a more challenging benchmark.