 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Error Scaling in Machine Learning on Natural Discrete Combinatorial Mutation-prone Sets: Case Studies on Peptides and Small Molecules
Paper and Code
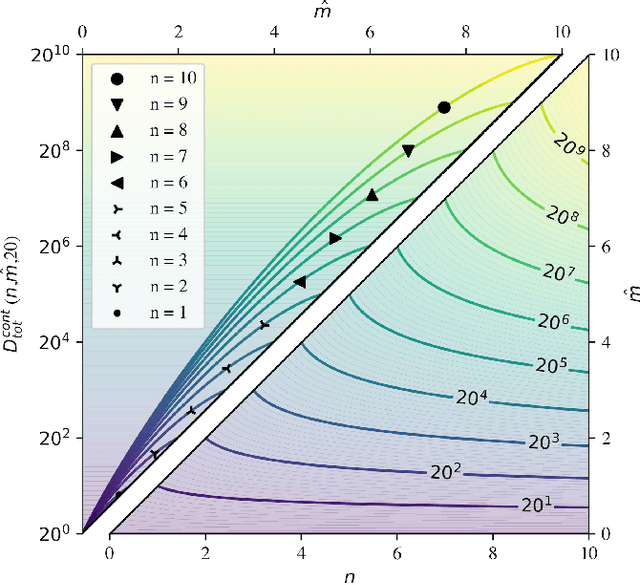
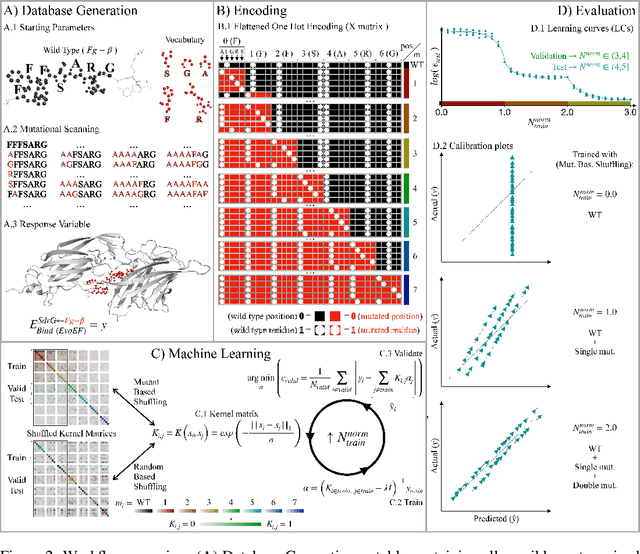
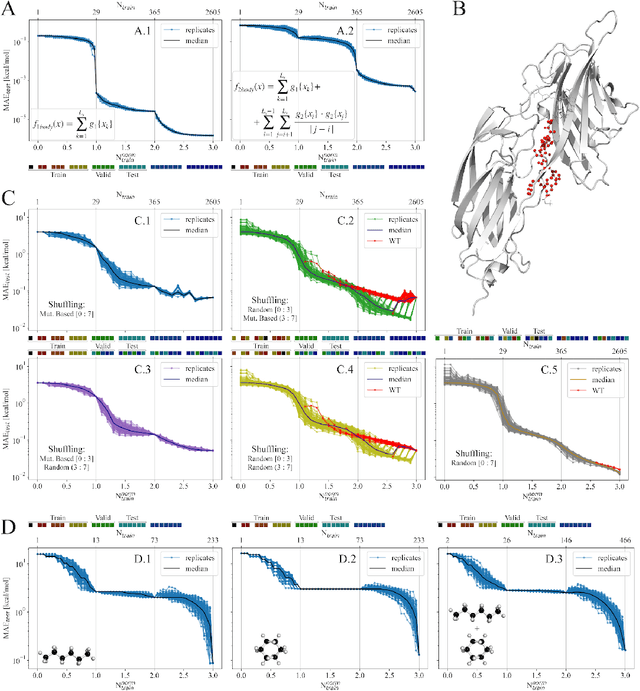
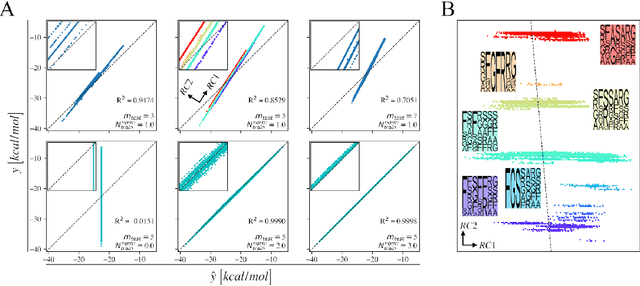
We investigate trends in the data-error scaling behavior of machine learning (ML) models trained on discrete combinatorial spaces that are prone-to-mutation, such as proteins or organic small molecules. We trained and evaluated kernel ridge regression machines using variable amounts of computationally generated training data. Our synthetic datasets comprise i) two na\"ive functions based on many-body theory; ii) binding energy estimates between a protein and a mutagenised peptide; and iii) solvation energies of two 6-heavy atom structural graphs. In contrast to typical data-error scaling, our results showed discontinuous monotonic phase transitions during learning, observed as rapid drops in the test error at particular thresholds of training data. We observed two learning regimes, which we call saturated and asymptotic decay, and found that they are conditioned by the level of complexity (i.e. number of mutations) enclosed in the training set. We show that during training on this class of problems, the predictions were clustered by the ML models employed in the calibration plots. Furthermore, we present an alternative strategy to normalize learning curves (LCs) and the concept of mutant based shuffling. This work has implications for machine learning on mutagenisable discrete spaces such as chemical properties or protein phenotype prediction, and improves basic understanding of concepts in statistical learning theory.