 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Machine Learning in Quantum Information Science
Paper and Code
Jan 22, 2022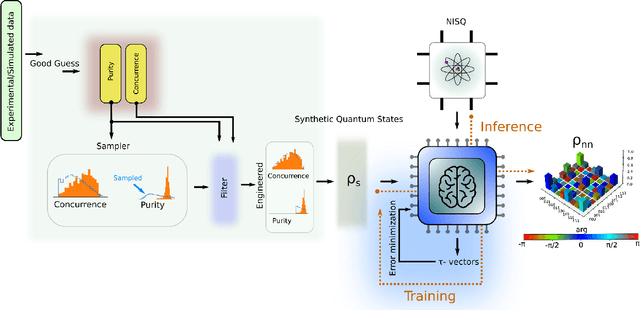
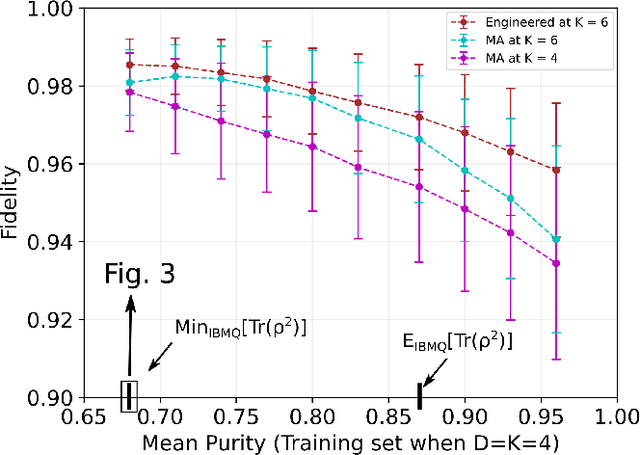
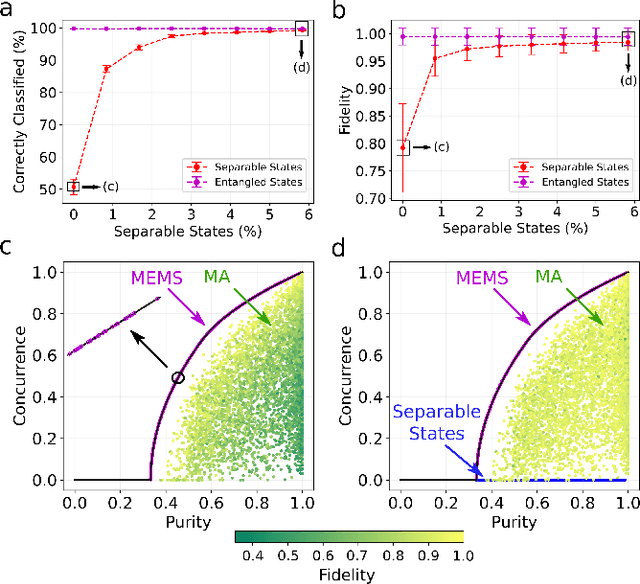
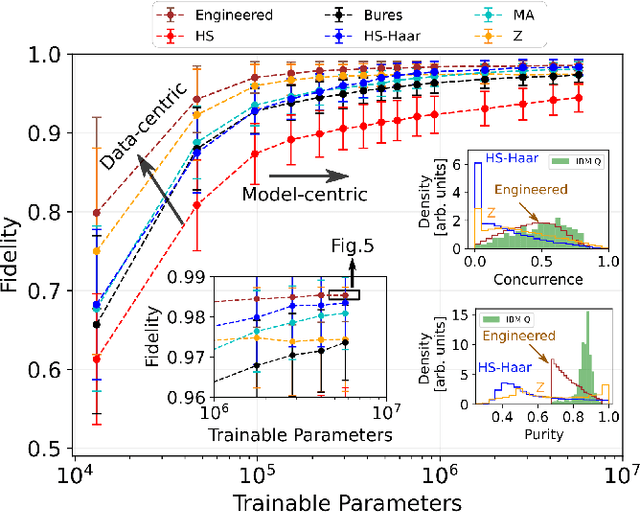
We propose a series of data-centric heuristics for improving the performance of machine learning systems when applied to problems in quantum information science. In particular, we consider how systematic engineering of training sets can significantly enhance the accuracy of pre-trained neural networks used for quantum state reconstruction without altering the underlying architecture. We find that it is not always optimal to engineer training sets to exactly match the expected distribution of a target scenario, and instead, performance can be further improved by biasing the training set to be slightly more mixed than the target. This is due to the heterogeneity in the number of free variables required to describe states of different purity, and as a result, overall accuracy of the network improves when training sets of a fixed size focus on states with the least constrained free variables. For further clarity, we also include a "toy model" demonstration of how spurious correlations can inadvertently enter synthetic data sets used for training, how the performance of systems trained with these correlations can degrade dramatically, and how the inclusion of even relatively few counterexamples can effectively remedy such problems.