 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Aggregation for Reducing Training Data in Symbolic Regression
Paper and Code
Aug 24, 2021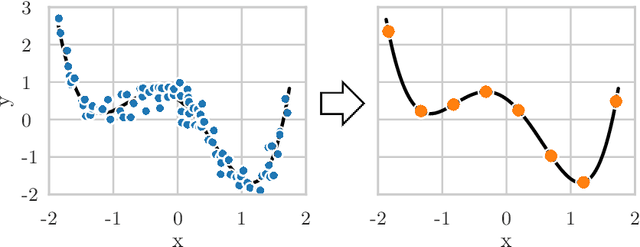
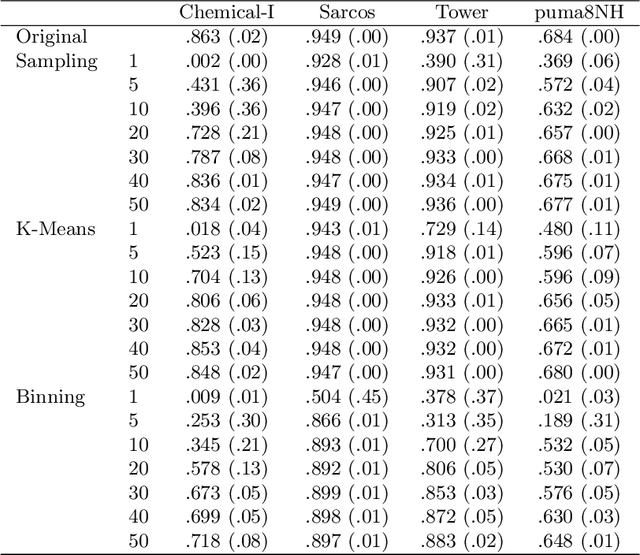
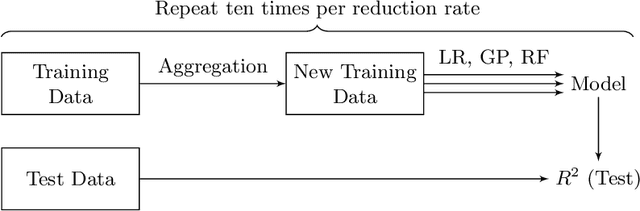
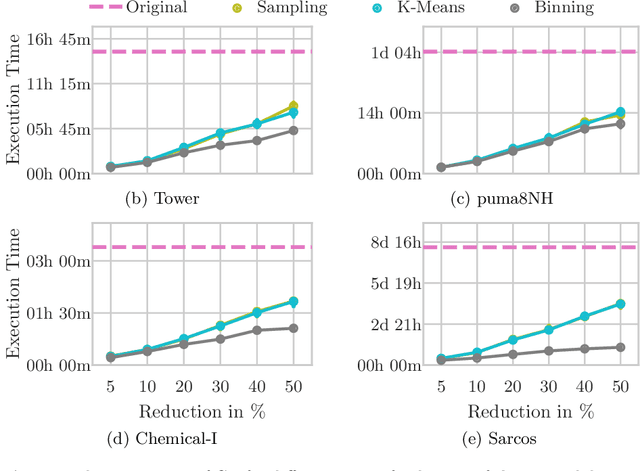
The growing volume of data makes the use of computationally intense machine learning techniques such as symbolic regression with genetic programming more and more impractical. This work discusses methods to reduce the training data and thereby also the runtime of genetic programming. The data is aggregated in a preprocessing step before running the actual machine learning algorithm. K-means clustering and data binning is used for data aggregation and compared with random sampling as the simplest data reduction method. We analyze the achieved speed-up in training and the effects on the trained models test accuracy for every method on four real-world data sets. The performance of genetic programming is compared with random forests and linear regression. It is shown, that k-means and random sampling lead to very small loss in test accuracy when the data is reduced down to only 30% of the original data, while the speed-up is proportional to the size of the data set. Binning on the contrary, leads to models with very high test error.