 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALL-E-Bot: Introducing Web-Scale Diffusion Models to Robotics
Paper and Code
Oct 05, 2022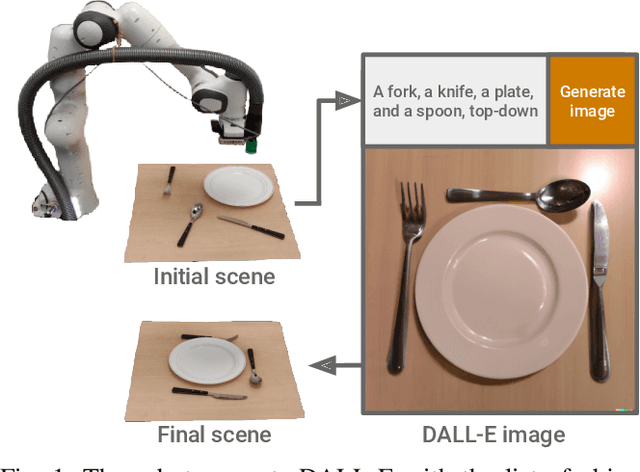
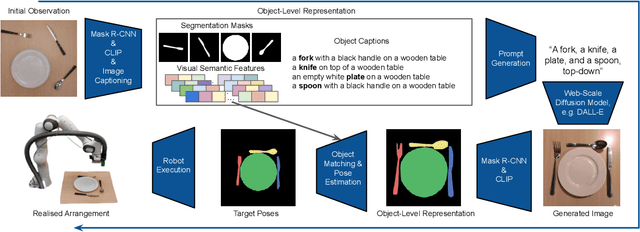

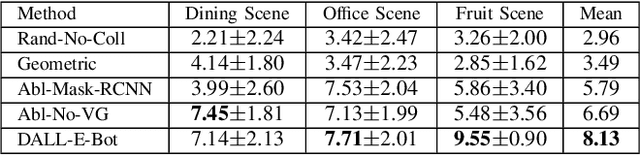
We introduce the first work to explore web-scale diffusion models for robotics. DALL-E-Bot enables a robot to rearrange objects in a scene, by first inferring a text description of those objects, then generating an image representing a natural, human-like arrangement of those objects, and finally physically arranging the objects according to that image. The significance is that we achieve this zero-shot using DALL-E, without needing any further data collection or training. Encouraging real-world results with human studies show that this is an exciting direction for the future of web-scale robot learning algorithms. We also propose a list of recommendations to the text-to-image community, to align further developments of these models with applications to robotics. Videos are available at: https://www.robot-learning.uk/dall-e-bot