 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-Consistent Counterfactuals by Latent Transformations
Paper and Code
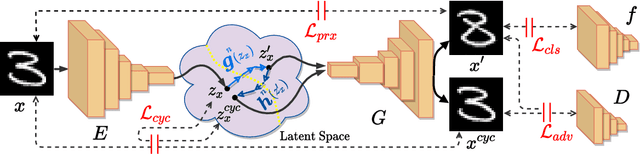



CounterFactual (CF) visual explanations try to find images similar to the query image that change the decision of a vision system to a specified outcome. Existing methods either require inference-time optimization or joint training with a generative adversarial model which makes them time-consuming and difficult to use in practice. We propose a novel approach, Cycle-Consistent Counterfactuals by Latent Transformations (C3LT), which learns a latent transformation that automatically generates visual CFs by steering in the latent space of generative models. Our method uses cycle consistency between the query and CF latent representations which helps our training to find better solutions. C3LT can be easily plugged into any state-of-the-art pretrained generative network. This enables our method to generate high-quality and interpretable CF images at high resolution such as those in ImageNet. In addition to several established metrics for evaluating CF explanations, we introduce a novel metric tailored to assess the quality of the generated CF examples and validate the effectiveness of our method on an extensive set of experiments.