 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVTT: Cross-Validation Through Time
Paper and Code
May 11, 2022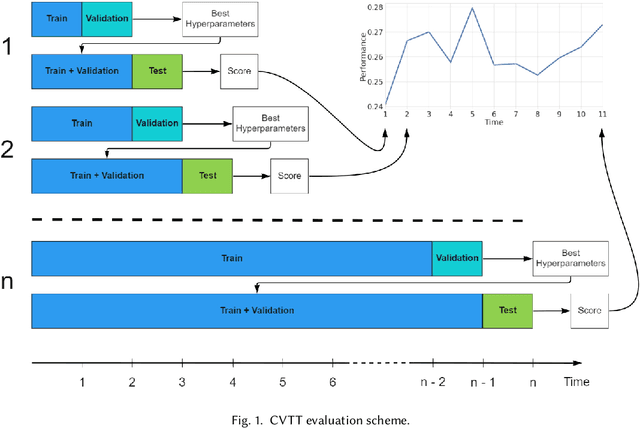
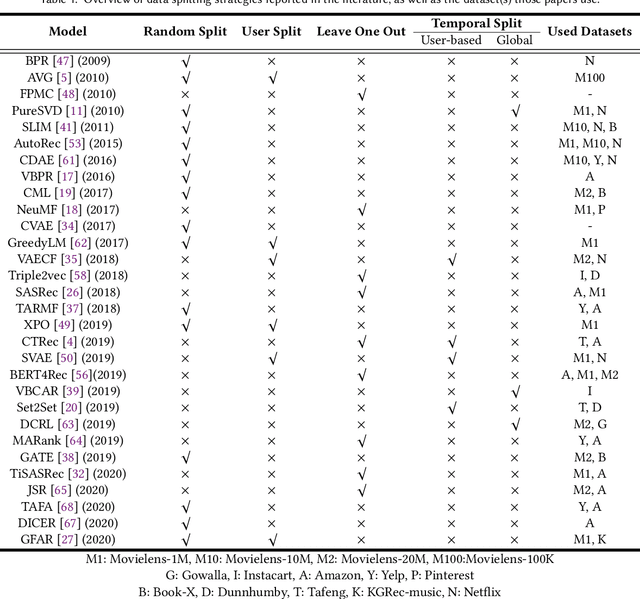

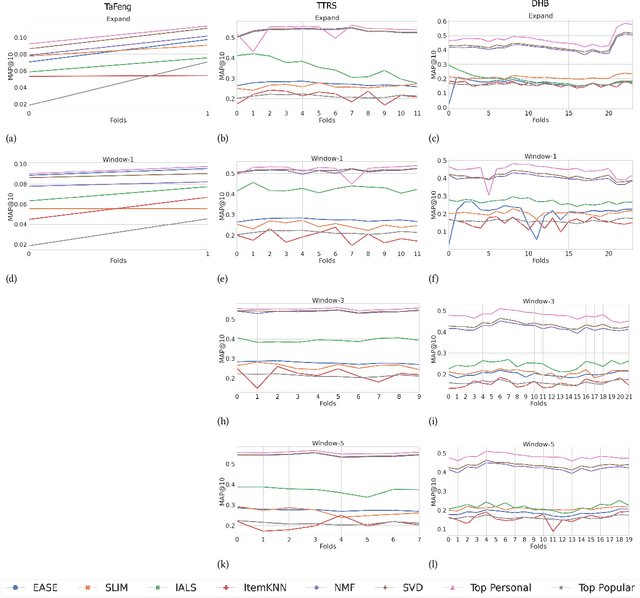
The practical aspects of evaluating recommender systems is an actively discussed topic in the research community. While many current evaluation techniques bring performance down to a single-value metric as a straightforward approach for model comparison, it is based on a strong assumption of the methods' stable performance over time. In this paper, we argue that leaving out a method's continuous performance can lead to losing valuable insight into joint data-method effects. We propose the Cross-Validation Thought Time (CVTT) technique to perform more detailed evaluations, which focus on model cross-validation performance over time. Using the proposed technique, we conduct a detailed analysis of popular RecSys algorithms' performance against various metrics and datasets. We also compare several data preparation and evaluation strategies to analyze their impact on model performance. Our results show that model performance can vary significantly over time, and both data and evaluation setup can have a marked effect on it.